Google Cloud’s Text-to-Speech and Speech-to-Text APIs are getting a bunch of updates today that introduce support for more languages, make it easier to hear auto-generated voices on different speakers and that promise better transcripts thanks to improved tools for speaker recognition, among other things.
With this update, the Cloud Text-to-Speech API is now also generally available.
Let’s look at the details. The highlight of the release for many developers is probably the launch of the 17 new WaveNet-based voices in a number of new languages. WaveNet is Google’s technology for using machine learning to create these text-to-speech audio files. The result of this is a more natural sounding voice.
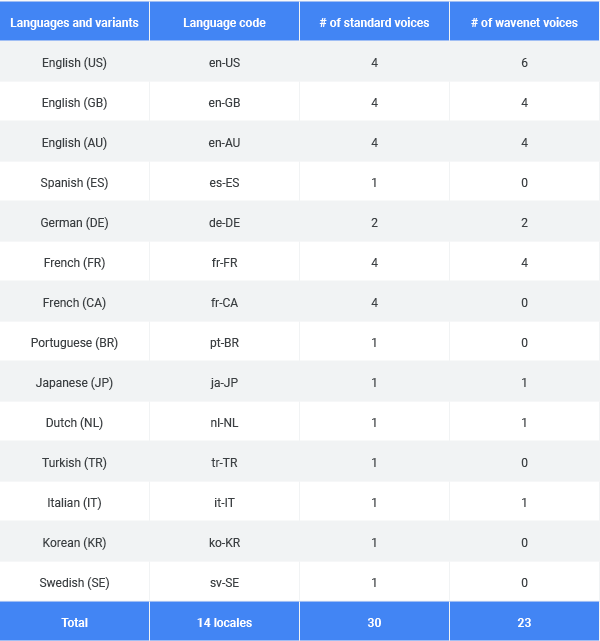
With this update, the Text-to-Speech API now supports 14 languages and variants and features a total of 30 standard voices and 26 WaveNet voices.
If you want to try out the new voices, you can use Google’s demo with your own text here.
Another interesting new feature here is the beta launch of audio profiles. The idea here is to optimize the audio file for the medium you’ll use to play it. Your phone’s speaker is different from the soundbar underneath your TV, after all. With audio profiles, you can optimize the audio for phone calls, headphones and speakers, for example.

On the Speech-to-Text side, Google is now making it easier for developers to transcribe samples with multiple speakers. Using machine learning, the service can now recognize the different speakers (though you still have to tell it how many speakers there are in a given sample) and it’ll then tag every word with a speaker number. If you have a stereo file of two speakers (maybe a call center agent on the left and the angry customer who called to complain on the right), then Google can now use those channels to distinguish between speakers, too.
Also new is support for multiple languages. That’s something Google’s Search App already supports and the company is now making this available to developers, too. Developers can choose up to four languages and the Speech-to-Text API will automatically determine which language is spoken.
And finally, the Speech-to-Text API now also returns word-level confidence scores. That may sound like a minor thing — and it already returned scores for each segment of speech — but Google notes that developers can now use this to build apps that focus on specific words. “For example, if a user inputs ‘please setup a meeting with John for tomorrow at 2PM’ into your app, you can decide to prompt the user to repeat ‘John’ or ‘2PM,’ if either have low confidence, but not to reprompt for ‘please’ even if has low confidence since it’s not critical to that particular sentence,” the team explains.
Read Full Article
No comments:
Post a Comment