It’s hard to shake the sense that the smart speaker market would look considerably different had the HomePod Mini arrived several years back. It’s not so much that the device is transformative on the face of it, but it’s impossible to deny that it marks a dramatically different approach to the category than the one Apple took almost three years ago with the launch of the original model.
Apple has never been a particular budget-conscious company when it comes to hardware — terms like “Apple tax” don’t spring out of nothing. But the last few years have seen the company soften that approach in an effort to appeal to users outside its traditional core of creative professionals. The iPhone and Apple Watch have both seen the company more aggressively pushing to appeal to entry-level users. It only follows that it would follow suit with its smart speaker.
Couple that with the fact that the Echo Dot and Google/Nest Home minis pretty consistently rate as the best-selling smart speakers for their respective company, and arrival of a HomePod Mini was all but inevitable, as Apple looks to take a bite out of the global smart speaker market, which currently ranks Amazon and Google at around 40% a piece. It’s going to be an uphill battle for the HomePod, but the Mini is, simply put, its strongest push in that direction to date.
Launched in early 2018 (after delays), the HomePod was a lot of things — but no one ever claimed it was cheap (though no doubt they found a way to spin it as a good deal). The $349 price tag (since reduced to $299) was hundreds of dollars more than the most expensive models from Amazon and Google. The HomePod was a premium device, and that was precisely the point. Music has always been a cornerstone of Apple’s philosophy, and the HomePod was the company’s way of embracing the medium without cutting corners.

Image Credits: Brian Heater
As Matthew wrote in a David Foster Wallacesque “four sentence” review, “Apple’s HomePod is easily the best sounding mainstream smart speaker ever. It’s got better separation and bass response than anything else in its size and boasts a nuance and subtlety of sound that pays off the seven years Apple has been working on it.”
He called it “incredibly over-designed and radically impressive,” while bemoaning limited Siri functionality. On the whole, the HomePod did a good job in being what it set out to be — but it was never destined to be the world’s best-selling smart speaker. Not at that price. What it did do, however, was help convince the rest of the industry that a smart speaker should be, above all, a speaker, rather than simply a smart assistant delivery device. The last several generations of Amazon and Google products have, accordingly, mostly brought sound to the forefront of product concerns.
Essentially, Amazon and Google have become more focused on sound and Apple more conscious of price. That’s not to say, however, that the companies have met somewhere in the middle. This is not, simply put, the Apple Echo Dot. The HomePod Mini is still, in many ways, a uniquely Apple product. There’s a focus on little touches that offer a comparably premium experience for its price point.
That price point being $99. That puts the device in league with the standard Amazon Echo and Google Nest, rather than their respective budget-level counterparts. Those devices run roughly half that price and are both fairly frequently — and quite deeply — discounted. In fact, those devices could nearly fall into the category of loss leaders for their respective companies — dirt-cheap ways to get their smart assistants into users’ homes. Apple doesn’t appear particularly interested in that approach. Not for the time being, at least. Apple wants to sell you a good speaker.
And you know what? The HomePod Mini is a surprisingly good speaker. Not just for its price, but also its size. The Mini is nearly exactly the same size as the new, round Echo Dot — which is to say, roughly the size of a softball. There are, however, some key differences in their respective designs. For starters, Amazon moved the Echo’s status ring to the bottom of the device, so as to not impede on its perfectly spherical design. Apple, on the other hand, simply lopped off the top. I was trying to figure out what it reminds me of, and this was the best I came up with.

Image Credits: Brian Heater
The design decision keeps the product more in line with the original HomePod, with an Aurora Borealis of swirling lights up top to show you when Siri is doing her thing. It also allows for the inclusion of touch-sensitive volume buttons and the ability to tap the surface to play/pause music. Rather than the fabric-style covering that has dominated the last several generations of Google and Amazon products, the Mini is covered in the same sort of audio-conductive mesh material as the full-size HomePod.
The device comes in white or space gray, and unlike other smart speakers, seems to be less about blending in than showing off. Of course, being significantly smaller than the HomePod makes it considerably more versatile. I’ve been using one of the two Minis Apple sent on my desk at home, and it’s an ideal size. On the bottom is a hard plastic base with an Apple logo.
There’s a long, non-detachable fabric cable. It would be nice if the cord was user-detectable, so you can swap it out as needed, but no go. The cable sports a USB-C connector, however, which makes it fairly versatile on that end. There’s also a 20W power adapter in the box (admittedly, not a sure bet with Apple, these days). It’s disappointing — but not surprising that there’s no auxiliary input on-board — there wasn’t one on the standard HomePod, either.

Image Credits: Brian Heater
Where Amazon switched to a front-facing speaker for the new Echo, Apple continues to focus on 360-degree sound. Your preference may depend on where you place the speaker, but this model is more versatile, especially if you’re not just seated in front of the speaker all day. I’ve used a lot of different smart speakers in my day, and honestly, I’m really impressed with the sound the company was able to get out of the 3.3-inch device.
It’s full and clear and impressively powerful for its size. Obviously that goes double if you opt for a stereo pair. Pairing is painless, out of the box. Just set up two devices for the same room of your home and it will ask you whether you want to pair them. From there, you can specify which one handles the right and left channels. If you’d like to spread out, the system will do multiroom audio by simply assigning speakers to different rooms. From there, you can just say, “Hey Siri, play music in the kitchen” or “Hey Siri, play music everywhere.” You get the picture.
In fact, the whole setup process is pretty simple with an iPhone. It’s quite similar to pairing AirPods: hold the phone near the speaker and you’ll get a familiar white popup guiding you through the process of setting it up, choosing the room and enabling voice recognition.
The speakers also get pretty loud, though if you need clear sound at a serious volume, I’d strongly recommend looking at something bigger (and pricier) like the original HomePod. For the living room of my one-bedroom in Queens, however, it does the trick perfectly, and sounds great from pretty much any angle in the room.
As a smart assistant, Siri is up to most of the basic tasks. There are also some neat tricks that leverage Apple’s unique ecosystem. You can, say, ask Siri to send images to your iPhone, and it’ll oblige, using Bing results. The fact of the matter is, however, that Amazon and Google got a pretty major head-start on the smart home assistant front and Apple is still catching up.
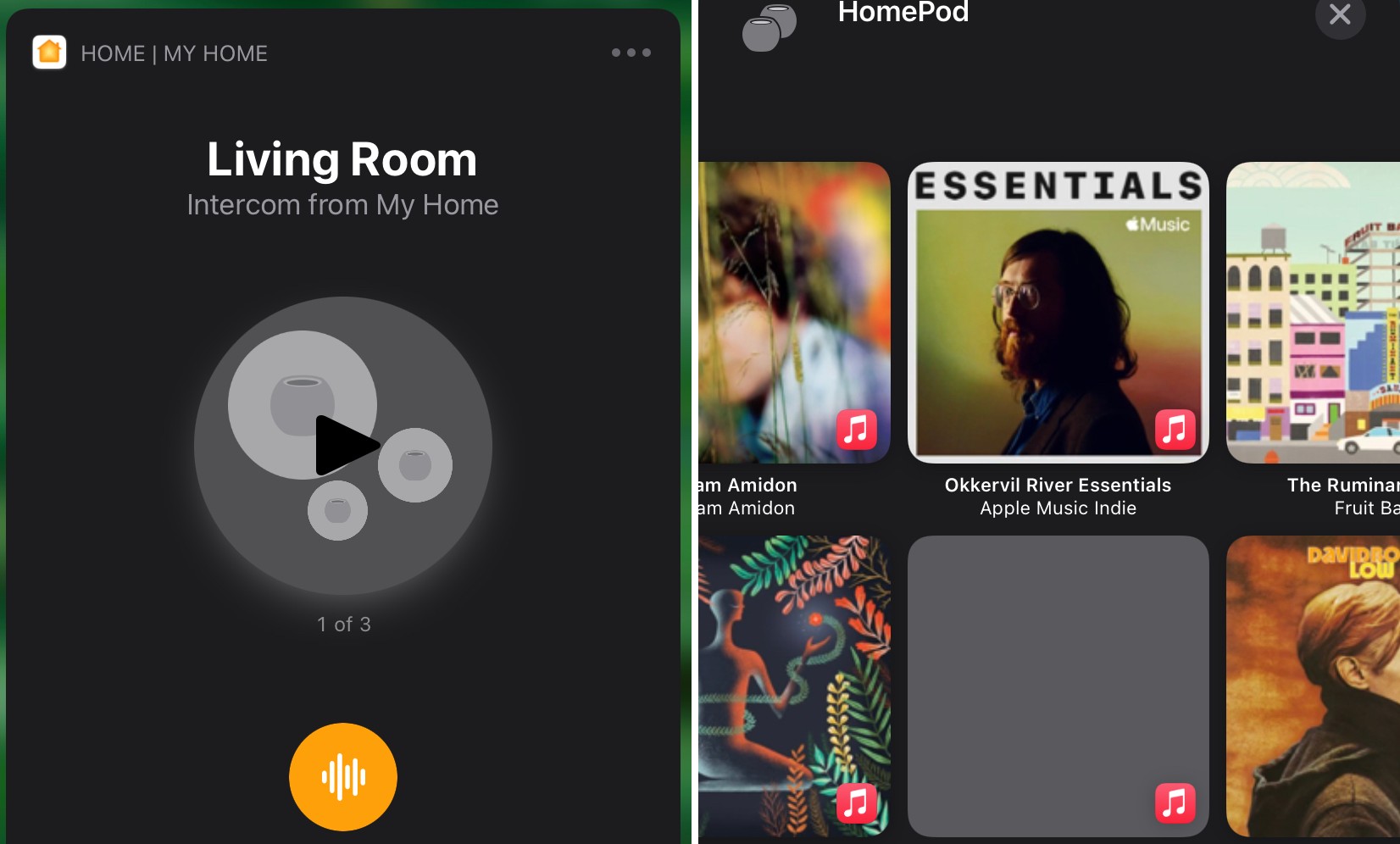
Image Credits: Brian Heater
There have, however, been some key strides of late — particularly as it pertains to Home/HomeKit. The last couple of iOS updates have brought some solid smart home updates; 14.1 brought intercom functionality specifically for HomePods and 14.2 extends that to other other devices. So you can say, “Hey Siri, intercom everyone, dinner is ready,” and beam it to various devices. The feature joins similar offerings from Amazon and Google, but does so on a wide range of (Apple) products, sending a pre-recorded snippet of your voice to the devices.
The system works out of the box with HomeKit-compatible devices — it’s a small list, compared to what’s currently offered for Alexa and Google Assistant, but it’s growing. You can check out the entire list of compatible smart home devices here.

Image Credits: Brian Heater
I found the voice recognition to be quite responsive to voice, even when the music is playing loud. Beyond Siri, there are a couple of ways to interact with the device. In addition to a single tap on the top to play/pause, a double-tap advances the track, triple-tap goes to the previous track and touching and holding fires up Siri. Unlike other smart speakers, there’s no physical button to turn off the mic — and you can’t ask Siri to do this either. The device is only listening for a “hey Siri” trigger and audio isn’t stored, but the feature would be nice for additional peace of mind.
You can also control music from your iPhone using AirPlay 2. That’s my preferred method, because I’m a bit of a micromanager when it comes to music. You’ll need to hit the AirPlay button to do that — or you can simply hold the iOS device near the HomePod Mini to take advantage of handoff using the U1 chip (iPhone 11 or later). That’s a neat little trick.
As someone who’s more accustomed to using Spotify than Apple Music, one thing that tripped me up a bit, however, is that when you ask the HomePod to play music, it will pick up from the last time you verbally requested playback, rather than treating all of your Apple Music listening sessions as a single stream. I prefer Spotify’s unified cross-device approach here.

Image Credits: Brian Heater
That said, a nice little iOS 14.2 addition brings your aggregated listening history (Apple Podcasts and Music) to a single stream accessible by long-pressing your HomePod in the Home app. From there you can tap on an album or podcast to automatically send them to the smart speaker.
All told, I’ve quite enjoyed my time with the little smart speaker. As I noted at the top, it’s hard not to wonder what might have been if Apple had launched the Mini alongside the initial HomePod. I suspect the company would still be a ways from market share domination, but the product really could have eaten into Amazon and Google’s lead. Instead, Apple waited — likely in hopes of getting the package right. That’s certainly understandable. Apple’s never been one to rush into a product, and the HomePod Mini sounds all the better for it.
 Read Full Article
Read Full Article