After a week in which it looked like activist investor Elliott Management might try to force out Jack Dorsey as CEO of Twitter to help boost the social platform’s flagging growth, it looks like we have a truce of sorts between the two.
Today, Twitter announced has received a $1 billion investment from Silver Lake, one of the tech industry’s most prolific investors. And as part of that deal, it has also entered into an agreement with Elliott — which owns about 4% of Twitter — to use that investment plus cash on hand toward a $2 billion share repurchase program. Along with that, there are two new people joining Twitter’s board of directors, Silver Lake’s Egon Durban and Elliott’s Jesse Cohn; the company said it is also seeking a third person to join as part of the agreement. It also committed itself to a plan to grow its mDAU (a special metric Twitter uses for “monetizable” daily active users) at 20% or more, with revenue growth accelerating on a year-over-year basis.
Twitter’s stock is down nearly 6% in pre-market trading, which might be in response to this news, but more likely is being mitigated in what is an overall very tough morning for publicly traded stocks in the wake of uncertainty over COVID-19.
In any event, the news of the investment and subsequent deal put an end — at least for now — to the possibility of Twitter co-founder Jack Dorsey being removed as CEO of the company.
The threat was real enough that Dorsey took to the stage (and Twitter) at an investor conference to directly address some of the criticisms that he faced from investors and the public over how he manages the company. (Not all were convinced.) There were rumors that supporters were closing ranks in defense of Dorsey, and it seems that this is an attempt at mitigating a full-scale change (at least for now).
“Twitter serves the public conversation, and our purpose has never been more important,” Dorsey said today in a statement. “Silver Lake’s investment in Twitter is a strong vote of confidence in our work and our path forward. They are one of the most respected voices in technology and finance and we are fortunate to have them as our new partner and as a member of our Board. We welcome the support of Egon and Jesse, and look forward to their positive contributions as we continue to build a service that delivers for customers, and drives value for stakeholders.”
Twitter was clear to state that the agreement between Silver Lake, Elliott and the company will see the new directors unable to influence Twitter policies and rules and enforcement decisions. This is likely in relation to the implication that Elliott — started by a man called Paul Singer, who is often described as a “mega donor” to Republicans and Trump — might try to use its investment to steer Twitter to the Right side of the political spectrum, or at least make it more sympathetic to it.
Patrick Pichette, who is the independent director of the Twitter board, will become the chair of the committee to find another board member. “Twitter has undergone remarkable change over the last several years,” he said in a statement.
“We are deeply proud of our accomplishments and confident we are on the right path with Jack’s leadership and the executive team. As a Board, we regularly review and evaluate how Twitter is run, and while our CEO structure is unique, so is Jack and so is this Company. To continue to ensure strong governance, we are pleased to create a temporary Board committee that will build on our regular evaluation of Twitter’s leadership structure. This committee, which I will chair, will provide a fresh look at our various structures, and report the findings to our Board on an ongoing basis. In an environment where certainty is scarce, I can say with certainty that today we have taken steps to meaningfully strengthen what is already a world-class Board.”
Whether or not Pichette is one of the tacit supporters of the current leadership status quo, it seems that for now investors are willing to give Dorsey a shot, provided there is more active input from board members who are investors.
“Twitter’s revolutionary platform is a cornerstone of the public discourse,” said Durban, who is the co-CEO and managing partner of Silver Lake. “We are impressed by Jack’s tireless work over the last few years to solidify the leadership team, improve the product and strengthen the Company. We are excited to partner with Twitter as an investor and a member of the Board. Jack is a visionary leader, and a critical force behind Twitter’s ongoing evolution and growth. I look forward to working alongside the entire Board and the executive team to drive Twitter’s long-term innovation and success.”
Jesse Cohn, partner at Elliott Management, added: “Twitter is one of the most important platforms in the global dialogue, and one of the most innovative and unique technology companies in the world. We are pleased to have worked collaboratively with Twitter on this constructive engagement. We invested in Twitter because we see a significant opportunity for value creation at the Company. I am looking forward to working with Jack and the Board to help contribute to realizing Twitter’s full potential.”
Read Full Article



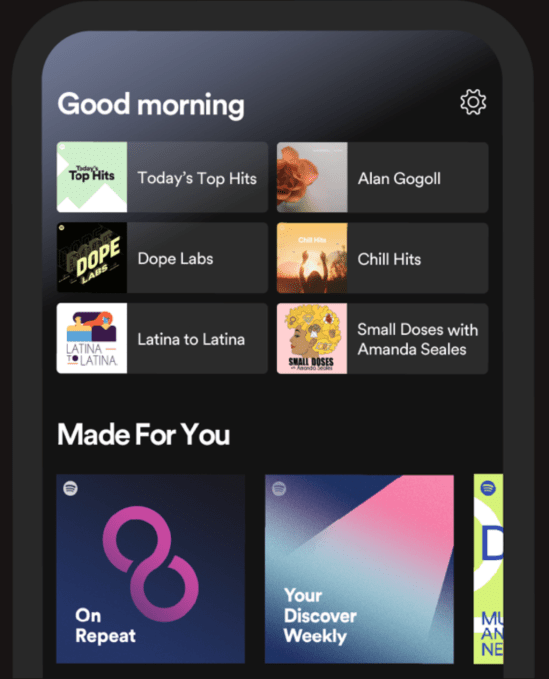 Now, the home screen reserves six spots underneath the daily greeting where you can pick back up with things like the podcast you stream every morning, your workout playlist, or the album you’ve been listening to on heavy rotation this week. This content will update as your day progresses to better match your activities and interests, based on prior behavior.
Now, the home screen reserves six spots underneath the daily greeting where you can pick back up with things like the podcast you stream every morning, your workout playlist, or the album you’ve been listening to on heavy rotation this week. This content will update as your day progresses to better match your activities and interests, based on prior behavior.