Earlier this year, Google’s in-house incubator launched CallJoy, a virtual customer service phone agent for small businesses that could block spammers, answer calls, provide callers with basic business information, and redirect other requests like appointment booking or to-go orders to SMS. Today, CallJoy is rolling out its first major update, which now enables the computer phone agent to have more of a conversation with the customer by asking questions and providing more information, among other improvements.
Originally, CallJoy could provide customers with information like the business hours or the address, or could ask the customer for permission to send them a link over text message to help them with their request. With the update, CallJoy’s phone agent can answer questions more intelligently.
This begins by CallJoy asking the customer, “can I help you?,” which the customer then responds to, as they would usually. Their answer allows CallJoy to offer more information than before, based on what the caller had said.
For example, if a caller asked a restaurant if they had any vegetarian options, the phone agent might respond: “Yes! Our menu has vegetarian and vegan-friendly choices. Can I text you the link to our online menu?”
This isn’t all done through some magical A.I., however. Instead, the business owner has to program in the sort of customer inquiries it wants CallJoy to be able to respond to and handle. While some, like vegetarian options, may be common inquiries, it can be hard to remember everything that customers ask. That where CallJoy’s analytics could help.
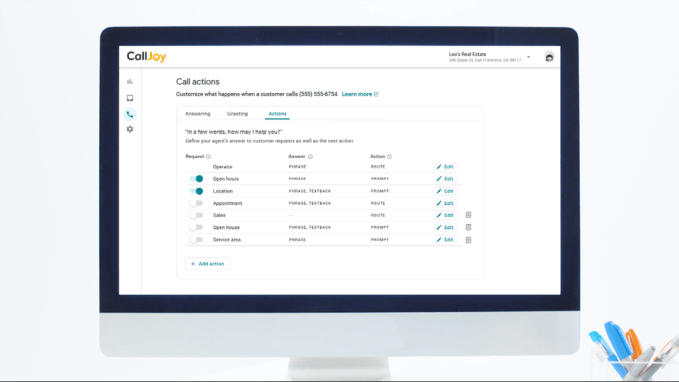
The service already gathers call data — like phone numbers, audio and call transcripts– into an online dashboard for further analysis. Business owners can tag calls and run reports to get a better understanding of their call volume, peak call times, and what people wanted to know. This information can be used to better staff their phone lines during busy times or to update their website or business listings, for example. And now, it can help the business owner to understand what sort of inquiries it should train the CallJoy phone agent on, too.
Once trained, the agent can speak an answer, send a link to the customer’s phone with the information, or offer to connect the caller to the business’s phone number to reach a real person. (CallJoy offers a virtual phone number, like Google Voice, but it can ring a “real” phone line as needed to get a person on the line.)
Another feature launching today will allow business owners to implement CallJoy as they see fit.
Some business owners may prefer to answer the phone themselves and speak to their customers directly, for example. But they could still take advantage of a service like this at other times — like after hours or when they’re too busy to answer. The updated version now allows them to program when CallJoy will answer, including by times of day, or after the phone rings a certain number of times, for example.
The business owner will also receive a daily email recap of everything CallJoy did, so they know how and when it was put to use.
The product to date has been aimed at small business owners, who can’t afford the more expensive customer service phone agent systems. Instead, it’s priced at a flat $39 per month.
A spokesperson for CallJoy says the service has signed up “thousands” of small businesses since its initially invite-only launch in May 2019.
Google’s Area 120 incubator is a place for Google employees to try out new ideas, while still operating inside Google instead of leaving for a startup. It’s considered a separate entity — some the apps produced by Area 120 don’t even mention their Google affiliation in their App Store descriptions, for instance. CallJoy, however, has received more of a spotlight than some. It’s even being featured on Google’s main corporate blog, The Keyword, today. However, if CallJoy makes the leap to Google — something that hasn’t been decided yet — it wouldn’t be the first Area 120 project to do so.
Area 120’s Touring Bird recently landed inside Google as did learn-to-code app Grasshopper and others.
We understand that joining Google is something that’s still on the table for CallJoy, but it’s not at the point of making that switch just yet.
Read Full Article











 But Instagram’s challenge will be retraining its populace to make premeditated, storyboarded social entertainment instead of just spontaneous, autobiographical social media like with Stories and feed posts.
But Instagram’s challenge will be retraining its populace to make premeditated, storyboarded social entertainment instead of just spontaneous, autobiographical social media like with Stories and feed posts.