While tremendous efforts are invested in improving the quality of videos taken with smartphone cameras, the quality of audio in videos is often overlooked. For example, the speech of a subject in a video where there are multiple people speaking or where there is high background noise might be muddled, distorted, or difficult to understand. In an effort to address this, two years ago we introduced Looking to Listen, a machine learning (ML) technology that uses both visual and audio cues to isolate the speech of a video’s subject. By training the model on a large-scale collection of online videos, we are able to capture correlations between speech and visual signals such as mouth movements and facial expressions, which can then be used to separate the speech of one person in a video from another, or to separate speech from background sounds. We showed that this technology not only achieves state-of-the-art results in speech separation and enhancement (a noticeable 1.5dB improvement over audio-only models), but in particular can improve the results over audio-only processing when there are multiple people speaking, as the visual cues in the video help determine who is saying what.
We are now happy to make the Looking to Listen technology available to users through a new audiovisual Speech Enhancement feature in YouTube Stories (on iOS), allowing creators to take better selfie videos by automatically enhancing their voices and reducing background noise. Getting this technology into users’ hands was no easy feat. Over the past year, we worked closely with users to learn how they would like to use such a feature, in what scenarios, and what balance of speech and background sounds they would like to have in their videos. We heavily optimized the Looking to Listen model to make it run efficiently on mobile devices, overall reducing the running time from 10x real-time on a desktop when our paper came out, to 0.5x real-time performance on the phone. We also put the technology through extensive testing to verify that it performs consistently across different recording conditions and for people with different appearances and voices.
From Research to Product
Optimizing Looking to Listen to allow fast and robust operation on mobile devices required us to overcome a number of challenges. First, all processing needed to be done on-device within the client app in order to minimize processing time and to preserve the user’s privacy; no audio or video information would be sent to servers for processing. Further, the model needed to co-exist alongside other ML algorithms used in the YouTube app in addition to the resource-consuming video recording itself. Finally, the algorithm needed to run quickly and efficiently on-device while minimizing battery consumption.
The first step in the Looking to Listen pipeline is to isolate thumbnail images that contain the faces of the speakers from the video stream. By leveraging MediaPipe BlazeFace with GPU accelerated inference, this step is now able to be executed in just a few milliseconds. We then switched the model part that processes each thumbnail separately to a lighter weight MobileNet (v2) architecture, which outputs visual features learned for the purpose of speech enhancement, extracted from the face thumbnails in 10 ms per frame. Because the compute time to embed the visual features is short, it can be done while the video is still being recorded. This avoids the need to keep the frames in memory for further processing, thereby reducing the overall memory footprint. Then, after the video finishes recording, the audio and the computed visual features are streamed to the audio-visual speech separation model which produces the isolated and enhanced speech.
We reduced the total number of parameters in the audio-visual model by replacing “regular” 2D convolutions with separable ones (1D in the frequency dimension, followed by 1D in the time dimension) with fewer filters. We then optimized the model further using TensorFlow Lite — a set of tools that enable running TensorFlow models on mobile devices with low latency and a small binary size. Finally, we reimplemented the model within the Learn2Compress framework in order to take advantage of built-in quantized training and QRNN support.
 |
| Our Looking to Listen on-device pipeline for audiovisual speech enhancement |
These optimizations and improvements reduced the running time from 10x real-time on a desktop using the original formulation of Looking to Listen, to 0.5x real-time performance using only an iPhone CPU; and brought the model size down from 120MB to 6MB now, which makes it easier to deploy. Since YouTube Stories videos are short — limited to 15 seconds — the result of the video processing is available within a couple of seconds after the recording is finished.
Finally, to avoid processing videos with clean speech (so as to avoid unnecessary computation), we first run our model only on the first two seconds of the video, then compare the speech-enhanced output to the original input audio. If there is sufficient difference (meaning the model cleaned up the speech), then we enhance the speech throughout the rest of the video.
Researching User Needs
Early versions of Looking to Listen were designed to entirely isolate speech from the background noise. In a user study conducted together with YouTube, we found that users prefer to leave in some of the background sounds to give context and to retain some the general ambiance of the scene. Based on this user study, we take a linear combination of the original audio and our produced clean speech channel: output_audio = 0.1 x original_audio + 0.9 x speech. The following video presents clean speech combined with different levels of the background sounds in the scene (10% background is the balance we use in practice).
Below are additional examples of the enhanced speech results from the new Speech Enhancement feature in YouTube Stories. We recommend watching the videos with good speakers or headphones.
Fairness Analysis
Another important requirement is that the model be fair and inclusive. It must be able to handle different types of voices, languages and accents, as well as different visual appearances. To this end, we conducted a series of tests exploring the performance of the model with respect to various visual and speech/auditory attributes: the speaker’s age, skin tone, spoken language, voice pitch, visibility of the speaker’s face (% of video in which the speaker is in frame), head pose throughout the video, facial hair, presence of glasses, and the level of background noise in the (input) video.
For each of the above visual/auditory attributes, we ran our model on segments from our evaluation set (separate from the training set) and measured the speech enhancement accuracy, broken down according to the different attribute values. Results for some of the attributes are summarized in the following plots. Each data point in the plots represents hundreds (in most cases thousands) of videos fitting the criteria.
 |
| Speech enhancement quality (signal-to-distortion ratio, SDR, in dB) for different spoken languages, sorted alphabetically. The average SDR was 7.89 dB with a standard deviation of 0.42 dB — deviation that for human listeners is considered hard to notice. |
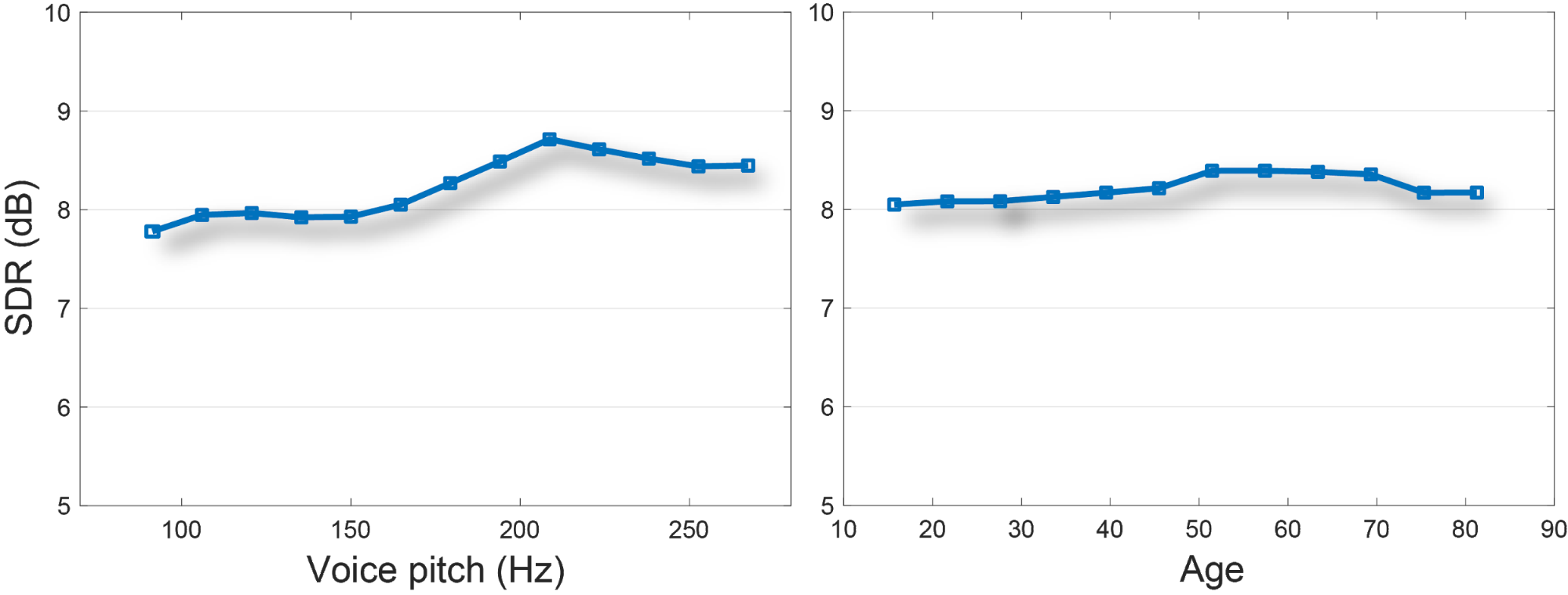 |
| Left: Speech enhancement quality as a function of the speaker’s voice pitch. The fundamental voice frequency (pitch) of an adult male typically ranges from 85 to 180 Hz, and that of an adult female ranges from 165 to 255 Hz. Right: speech enhancement quality as a function of the speaker’s predicted age. |
 |
| As our method utilizes facial cues and mouth movements to isolate the speech, we tested whether facial hair (e.g., a moustache, beard) may obstruct those visual cues and affect the method’s performance. Our evaluations show that the quality of speech enhancement is maintained well also in the presence of facial hair. |
Using the Feature
YouTube creators who are eligible for YouTube Stories creation may record a video on iOS, and select “Enhance speech” from the volume controls editing tool. This will immediately apply speech enhancement to the audio track and will play back the enhanced speech in a loop. It is then possible to toggle the feature on and off multiple times to compare the enhanced speech with the original audio.

In parallel to this new feature in YouTube, we are also exploring additional venues for this technology. More to come later this year — stay tuned!
Acknowledgements
This feature is a collaboration across multiple teams at Google. Key contributors include: from Research-IL: Oran Lang; from VisCAM: Ariel Ephrat, Mike Krainin, JD Velasquez, Inbar Mosseri, Michael Rubinstein; from Learn2Compress: Arun Kandoor; from MediaPipe: Buck Bourdon, Matsvei Zhdanovich, Matthias Grundmann; from YouTube: Andy Poes, Vadim Lavrusik, Aaron La Lau, Willi Geiger, Simona De Rosa, and Tomer Margolin.

No comments:
Post a Comment