Roblox, which allows kids to create 3D worlds and games, has raised an additional $150 million in funding.
The company didn’t disclose its valuation in the announcement, but a source with knowledge of the deal told us that it valued Roblox at more than $2.5 billion — the price that Microsoft paid to acquire Minecraft four years ago.
“This is a big year for us that fortifies the dream,” said co-founder and CEO David Baszucki.
“First and foremost, the reason to fundraise is to have a war chest, to have a buffer, to have the opportunity to do acquisitions, to have a strong balance sheet as we grow internationally,” he said.
In order to support that growth, Baszucki said Roblox will be opening offices in some regions like China (“most likely with a partner that hasn’t been announced yet”), but it also requires building out infrastructure like local language and local payment support.
Roblox has now raised a total of $400 million in funding, according to Crunchbase. The new round was led by Greylock Partners and Tiger Global, with participation from existing investors Altos Ventures, Index Ventures, Meritech Capital Partners and others.
Greylock’s David Sze has had big successes in both gaming and social media, having backed Facebook, LinkedIn, SGN and others. But he said Roblox is the first company he’s seen to “unify those two together on a platform in a magical kind of way.”
Apparently, Sze has known Baszucki for a long time — their kids went to the same school, and Sze remembered Baszucki bringing an early version of Roblox to the science fair. Gaming companies can be a risky investment, because their business relies on creating new hits, but Sze said Roblox is different.
“They aren’t making the games,” Sze said. “They’re letting the long tail of developers develop all the games on the platform, they’re let users decide what the successes are. It’s much more like a YouTube or much more like an Apple with the App Store.”
In a blog post about the funding, Sze even suggested that some of the next big gaming franchises could emerge from the Roblox platform, a prediction he repeated in our interview
“I’d be surprised if there aren’t some huge, high quality games that aren’t originated on Roblox in the next three-to-five years,” he said.
Roblox says it now has more than 70 million monthly active users, with more than 4 million creators who have built more than 40 million-plus experiences.
Asked whether these risks gave him any pause, Sze said, “User protection, user safety, all the aspects of having of having youth on your platform, it takes those things extremely seriously.”
“Are we perfect? No,” he said. “But I can tell you from inside the company that it’s an incredibly high priority. They’ve already done lots of things to help protect and make the user experience the best, and they have a list of stuff that they’re already working on.”
I’ll be interviewing Baszucki on-stage at Disrupt SF this afternoon, so stay tuned to TechCrunch (or come on out to the event!) for more on the funding and his future plans.
Posted by Piyush Sharma, Software Engineer and Radu Soricut, Research Scientist, Google AI
The web is filled with billions of images, helping to entertain and inform the world on a countless variety of subjects. However, much of that visual information is not accessible to those with visual impairments, or with slow internet speeds that prohibit the loading of images. Image captions, manually added by website authors using Alt-text HTML, is one way to make this content more accessible, so that a natural-language description for images that can be presented using text-to-speech systems. However, existing human-curated Alt-text HTML fields are added for only a very small fraction of web images. And while automatic image captioning can help solve this problem, accurate image captioning is a challenging task that requires advancing the state of the art of both computer vision and natural language processing.
Today we introduce Conceptual Captions, a new dataset consisting of ~3.3 million image/caption pairs that are created by automatically extracting and filtering image caption annotations from billions of web pages. Introduced in a paper presented at ACL 2018, Conceptual Captions represents an order of magnitude increase of captioned images over the human-curated MS-COCO dataset. As measured by human raters, the machine-curated Conceptual Captions has an accuracy of ~90%. Furthermore, because images in Conceptual Captions are pulled from across the web, it represents a wider variety of image-caption styles than previous datasets, allowing for better training of image captioning models. To track progress on image captioning, we are also announcing the Conceptual Captions Challenge for the machine learning community to train and evaluate their own image captioning models on the Conceptual Captions test bed.
Generating the Dataset
To generate the Conceptual Captions dataset, we start by sourcing images from the web that have Alt-text HTML attributes. We automatically screen these for certain properties to ensure image quality while also avoiding undesirable content such as adult themes. We then apply text-based filtering, removing captions with non-descriptive text (such as hashtags, poor grammar or added language that does not relate to the image); we also discard texts with high sentiment polarity or adult content (for more details on the filtering criteria, please see our paper). We use existing image classification models to make sure that, for any given image, there is overlap between its Alt-text (allowing for word variations) and the labels that the image classifier outputs for that image.
From Specific Names to General Concepts
While candidates passing the above filters tend to be good Alt-text image descriptions, a large majority use proper names (for people, venues, locations, organizations etc.). This is problematic because it is very difficult for an image captioning model to learn such fine-grained proper name inference from input image pixels, and also generate natural-language descriptions simultaneously1.
To address the above problems we wrote software that automatically replaces proper names with words representing the same general notion, i.e., with their concept. In some cases, the proper names are removed to simplify the text. For example, we substitute people names (e.g., “Former Miss World Priyanka Chopra on the red carpet” becomes “actor on the red carpet”), remove locations names (“Crowd at a concert in Los Angeles” becomes “Crowd at a concert”), remove named modifiers (e.g., “Italian cuisine” becomes just “cuisine”) and correct newly formed noun phrases if needed (e.g., “artist and artist” becomes “artists”, see the example illustration below).
Illustration of text modification. Image by Rockoleando used under CC BY 2.0 license.
Finally, we cluster all resolved entities (e.g., “artist”, “dog”, “neighborhood”, etc.) and keep only the candidate types which have a count of over 100 mentions, a quantity sufficient to support representation learning for these entities. This retained around 16K entity concepts such as: “person”, “actor”, “artist”, “player” and “illustration”. Less frequent ones that we retained include “baguette”, “bridle”, “deadline”, “ministry” and “funnel”.
In the end, it required roughly one billion (English) webpages containing over 5 billion candidate images to obtain a clean and learnable image caption dataset of over 3M samples (a rejection rate of 99.94%). Our control parameters were biased towards high precision, although these can be tuned to generate an order of magnitude more examples with lower precision.
Dataset Impact
To test the usefulness of our dataset, we independently trained both RNN-based, and Transformer-based image captioning models implemented in Tensor2Tensor (T2T), using the MS-COCO dataset (using 120K images with 5 human annotated-captions per image) and the new Conceptual Captions dataset (using over 3.3M images with 1 caption per image). See our paper for more details on model architectures.
These models were tested using images from Flickr30K dataset (which are out-of-domain for both MS-COCO and Conceptual Captions), and the resulting captions evaluated using 3 human raters per test case. The results are reported in the table below.
From these results we conclude that models trained on Conceptual Captions generalized better than competing approaches irrespective of the architecture (i.e., RNN or Transformer). In addition, we found that Transformer models did better than RNN when trained on either dataset. The conclusion from these findings is that Conceptual Captions provides the ability to train image captioning models that perform better on a wide variety of images.
Get Involved
It is our hope that this dataset will help the machine learning community advance the state of the art in image captioning models. Importantly, since no human annotators were involved in its creation, this dataset is highly scalable, potentially allowing the expansion of the dataset to enable automatic creation of Alt-text-HTML-like descriptions for an even wider variety of images. We encourage all those interested to partake in the Conceptual Captions Challenge, and we look forward to seeing what the community can do! For more details and the latest results please visit the challenge website.
Acknowledgements Thanks to Nan Ding, Sebastian Goodman and Bo Pang for training models with Conceptual Captions dataset, and to Amol Wankhede for driving the public release efforts for the dataset.
1 In our paper, we posit that if automatic determination of names, locations, brands, etc. from the image is needed, it should be done as a separate task that may leverage image meta-information (e.g. GPS info), or complementary techniques such as OCR.↩
Watch an ad for the hottest new video game, and you’ll see those familiar words flash up at the end:
Pre-order now!
It seems that every publisher wants you to put down your cash for their new game months before release. You might do so instinctively, but we’re here to tell you why you should stop pre-ordering video games…
What Is Pre-Ordering?
In case you’re not familiar with the practice, pre-ordering a video game is the act of paying for a game before it’s even released. You can do so with a physical copy as well as a digital copy of the game.
Typically, when you pre-order a physical copy, you don’t pay the full amount upfront. In-store, GameStop will take a minimum of $5 to reserve a copy, then you pay the balance when you pick it up. Pre-ordering from Amazon charges your card for the full amount once your order ships.
Meanwhile, pre-ordering on the PlayStation Store charges you immediately. Xbox Games Store pre-orders use your account balance right away if you have in your wallet; otherwise it will charge your credit card around 10 days before launch.
When you pre-order a game, you’re paying for it upfront based on a marketing campaign or glossy pre-release trailer. Before the game releases, you have no reviews, footage from YouTube or Twitch, or other impressions to go off.
This is a problem because game trailers and other advertisements are not always true to the game’s final form. No Man’s Sky is the best example of this in recent years.
Released in 2016, No Man’s Sky is a procedurally generated space adventure game that the developers claimed could create up to 18 quintillion planets. It started off as a small indie venture and quickly grew into a much-hyped game when Sony got involved.
Upon release, No Man’s Sky received heavy criticism for lacking a lot of the promised content, and the developers went silent. A Reddit user even compiled a list of No Man’s Sky’s missing features.
No Man’s Sky sounded and looked amazing. Using screenshots and videos that weren’t actually from the finished product (known as “bullshots”) led to a false sense of the game’s quality. But hundreds of thousands of people were sorely disappointed when they bought it at full price.
2. You Pay the Highest Price
Games aren’t cheap. Most major releases cost $60 at launch, and that doesn’t include any DLC (downloadable content) released later. By pre-ordering, you pay the highest price for a game that in all likelihood will drop in cost shortly (especially if the game doesn’t receive good reviews).
Two years after No Man’s Sky’s botched launch, the game has received multiple major updates and is actually worth playing. But you can grab a copy for just $20 now. Often, games drop by as much as $20 just a few months after release.
As an example, I bought Horizon Zero Dawn: Complete Edition last week for $12. That includes the full game (originally $60), The Frozen Wilds expansion ($20), and other minor items that were only included in more expensive deluxe editions (more on that below).
Additionally, the discounts many game retailers offered for pre-ordering are gone. Amazon Prime used to offer 20% off if you pre-ordered a game or bought it within two weeks of release. It cut this back to pre-orders only a while ago, and recently changed the policy to instead provide a $10 Amazon credit for pre-ordering “select games.”
Starting August 28th, Amazon (Prime) is giving $10 Amazon credit for select game preorders. This is replacing the 20% off prime discount. Preorders placed before August 28th will still receive the 20% off discount https://t.co/JWGM2v7Kbppic.twitter.com/xY6igLHDQv
Meanwhile, Best Buy’s Gamer’s Club Unlocked program, which offered 20% off all new games and pre-orders, is gone too. Thus, pre-ordering doesn’t offer any real savings anymore.
Even worse, you’re locked into your decision if you pre-order digitally on PS4. The PlayStation Store states “cancellations and refunds are not available except where required by law” (good luck with that). However, the Xbox Games Store does allow you to cancel pre-orders.
3. You’re Supporting Lousy Practices
When you pre-order a game, you’re a guaranteed sale in the publisher’s eyes. Instead of having to guess how many people will buy the game, it has a good idea of the sales to expect.
This leads to the big game studios continuing bad practices. If they know the game will sell millions no matter what shape it’s in when released, why put the effort in? Assassin’s Creed Unity is a great example of a shamefully broken game that was still released.
Game demos, once an important way to try before you bought, are all but extinct. Why would a developer offer a demo when it knows you’re going to buy the game anyway? And with multiplayer-focused games, access to the beta is usually restricted to a pre-order bonus.
Similarly, lots of single-player games have exclusive missions and other content spread across retailers via pre-orders. Ordering from Walmart might grant one mission, while Target offers another. This slices up the game and makes it impossible to have everything at launch. The original Watch Dogs had so many editions that someone came up with a spreadsheet to keep track of them all.
— Franky Magic ????? (@NotFrankTurner) May 27, 2014
Some pre-order bonuses border on ridiculous. 2016’s Deus Ex: Mankind Divided had a ludicrous scheme where more people pre-ordering the game unlocked additional tiers of bonuses. At each tier, you picked between two rewards that you wanted, meaning that you couldn’t have everything. And to get it all, you had to buy the $150 collector’s edition.
Thankfully, this scheme was scrapped before launch. But it shows that you can’t put anything past game publishers when it comes to pre-orders.
Refuting Common Pre-Order Arguments
Now that we’ve discussed three major reasons pre-ordering isn’t worth it, let’s address some of the commonly-cited benefits of pre-ordering.
1. You Get a Guaranteed Copy
In its inception, pre-ordering was a solution to a problem. Shipping too many copies of a game is a waste, while not having enough means that some players might miss out. Pre-ordering, then, allowed stores to forecast how many copies they would need.
But once game series like Call of Duty exploded in popularity, pre-ordering became unnecessary. When a new game in a series like this releases, stores stock hundreds of copies. You can easily pick one up on release day without pre-ordering. Furthermore, you can always grab a digital copy.
2. Pre-Order Bonuses
Most pre-orders, especially for the limited or collector’s editions, include a bunch of extra items to incentivize you. These can include extra missions, cosmetics, or usable boosts. More expensive editions might even have a statue or art book included.
Almost all of the time, these pre-order bonuses are laughable. The exclusive missions are nothing special, and will likely appear in the inevitable “complete edition” a year down the road. As mentioned above, this is a shady practice because developers chop up parts of the game to sell as pre-order inventives.
Cosmetics don’t change anything about the game, and the figurines/art books are no rare gaming treasures—they’re almost always cheap junk and inferior to what you can find elsewhere. As an example, I regret buying the Pip-Boy edition of Fallout 4, which ended up being a dumb gimmick.
Even worse are the one-time boosts. A bit of extra XP or in-game consumables just gives you a head start and can even cheapen the early experience.
The pinnacle of this stupidity is Sonic Lost World, which gave you 25 extra lives for pre-ordering the game from Amazon. Not only are lives not a big deal in most games, but this takes a reward usually earned in-game and gives it to you for money. That’s low.
3. It’s a Franchise You Love
It’s tempting to pre-order a game from your favorite franchise, especially with the bonuses discussed above. You might think that it’s a safe bet to pre-order from a series you love, but this isn’t always the case.
You’ll probably luck out with a consistent series like Zelda or Grand Theft Auto. But you don’t have to look far to find disappointing entries in major franchises.
Resident Evil 6 was panned almost universally, and disappointed even diehard fans. Sonic Forces was a letdown (another mar on Sonic’s history). Even Batman: Arkham Knight, a great game in a respected series, had an atrocious PC port that basically rendered the game unplayable at launch.
Every game has the potential to be disappointing. Save yourself the money and heartache by avoiding pre-ordering, and reading reviews and thoughts from others first.
When Is It OK to Pre-Order?
I’ve argued why it’s a bad idea to pre-order in almost every case. But there are a few cases where it’s an understandable option.
One is if you’re pre-ordering an unknown game, especially if it’s an import from another region. If pre-ordering is the only way you know you’ll get a copy, go ahead and do so. But this is not the case for 99% of games or players.
Another is pre-ordering a digital copy so you can preload it. Most systems allow you to download a pre-ordered digital game before release so you can start playing at midnight.
While this can prove helpful to those with slower internet connections, the problem with gambling on the game’s quality are still a concern. Consider whether you really need to play the game at midnight, or if you can wait an extra day in order to check out the reviews on trusted gaming sites.
Pre-Ordering Doesn’t Benefit You
It’s vital to remember that pre-ordering isn’t for your benefit. Publishers and game retailers want you to pre-order so they can get as much of your money as early as possible. When you pre-order, you help cultivate the practice.
And just because you don’t play the newest games doesn’t mean you have to miss out. Reddit’s /r/PatientGamers is a community built around playing older games, so give it a look to see if waiting is the answer.
By avoiding pre-orders, you can save money on gaming, avoid buying disappointing games, and still get a copy of the titles you’re interested in. Sounds like a pretty good deal, no?
For ages, Google Earth has remained people’s go-to service for browsing our globe. All from the comfort of their home and couches. Google Earth was completely overhauled in 2017. And that introduced more virtual tours to the world’s most exotic places and cultures. This gives you a chance to learn more about them.
Here are the thirteen best virtual tours on Google Earth you should explore.
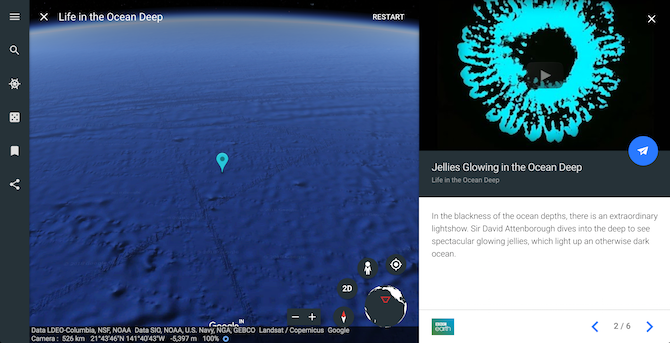
Discover mysterious sea creatures as the renowned naturalist with Sir David Attenborough. The renowned naturalist takes you through the depths of our oceans in a series of videos. Life in the Ocean Deep talks about a host of quirky, yet breathtaking creatures like jellies that glow in the dark, world’s largest crabs, and more.
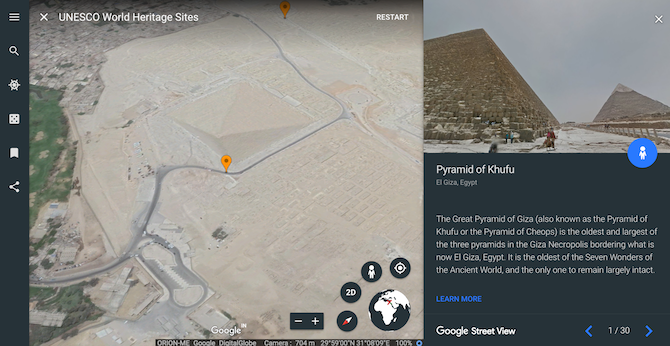
Follow along as Google Earth briefs you on thirty historic landmarks declared as World Heritage sites by UNESCO. The virtual tour provides quick summaries on each. This includes India’s Taj Mahal, Cambodia’s Towers of Angkor Wat, Seville’s Catedral de Sevilla, and others.
Don’t forget to plan your itineraries before embarking to explore all of these in real life.
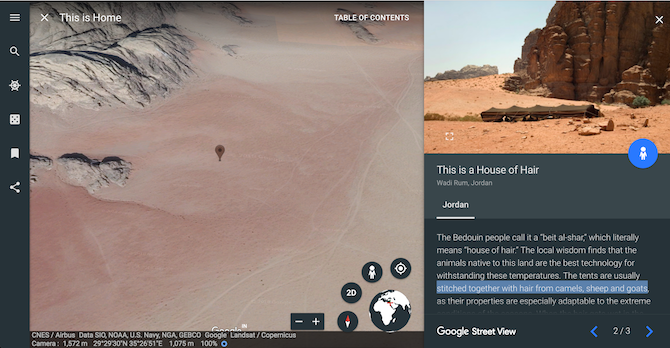
Take the This is Home virtual tour and visit traditional homes around the world. Get to know the history behind them from a vast range of countries. Glimpse inside these archaic structures with Street View. Some of these structures are situated in far-flung regions.
For instance, Jordan’s House of Hair is a string of tents stitched together with hair from camels, sheep, and goats and is located in the middle of a desert.
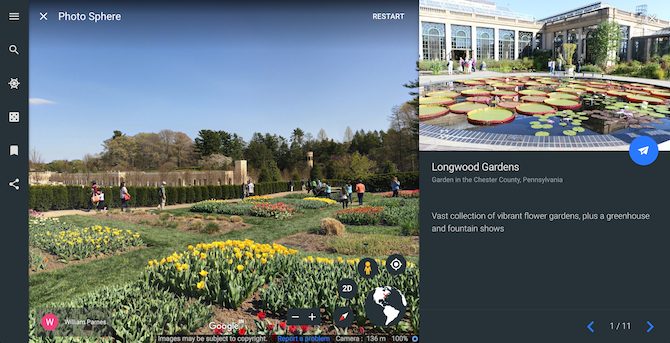
Stop and Smell the Flowers takes you on a journey around some of the most breathtaking botanical gardens and arboretums. The virtual tour highlights a total of eleven places from countries like Russia, Sweden, and more.
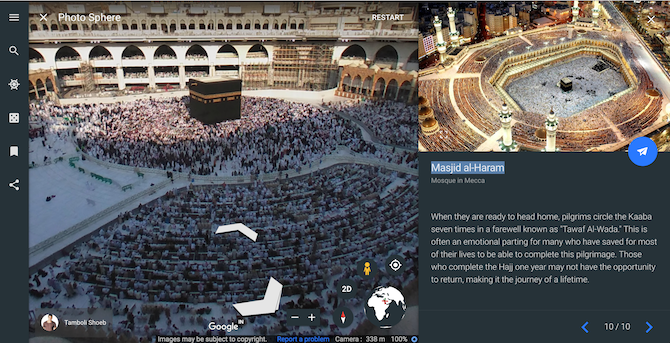
Every year, tens of thousands of Muslims embark on a pilgrimage to Mecca, a city considered the holiest in the religion. Google Earth’s virtual tour titled Pilgrimage to Mecca lets you virtually experience the hajj right from landing at the Hajj Terminal Jeddah Airport to the final destination which is the Masjid al-Haram, a mosque in Mecca.
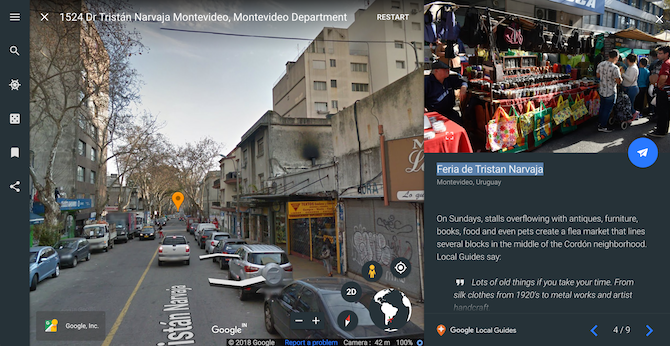
Have you ever had a fascination for bustling flea markets? Experience them with this virtual tour curated by Google Local Guides. Called Global Flea Markets, the tour walks you through nine of the most iconic markets worldwide such as France’s Les Puces de Saint-Ouen, India’s Anjuna Flea Market, Uruguay’s Feria de Tristan Narvaja, and others.
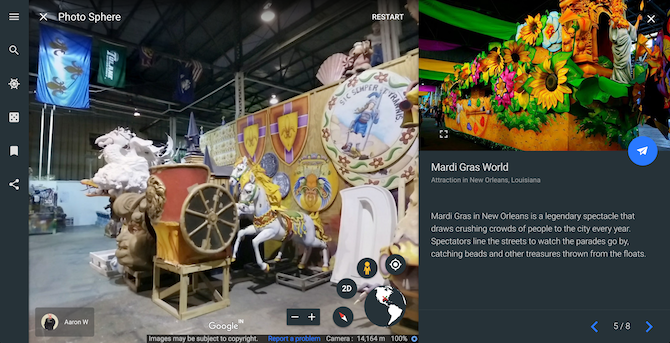
Being a land of diverse cultures and societies, the world is laden with numerous festivals and the most vibrant of them all are covered in Colorful Street Fests & Carnivals. The tour features eight of the biggest celebrations from around the globe such as the large-scale food fight called La Tomatina in Spain, Holi from India, Mardi Gras of New Orleans, and more.
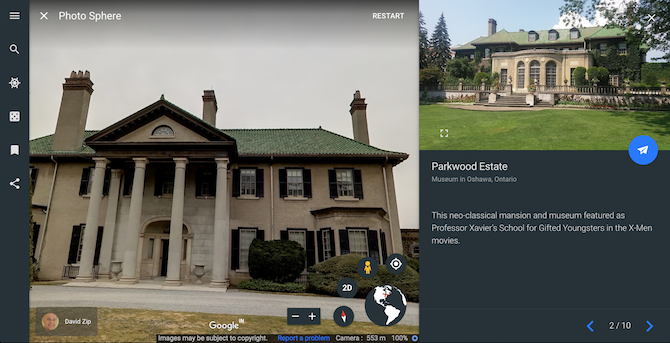
Unleash your inner geek on a virtual tour that takes you through a bunch of iconic comic book spots. The series curates a total of ten destinations known for either appearing in various fictional universes such as the Parkwood Estate, the neo-classical mansion used for Professor Xavier’s School for Gifted Youngsters in the X-Men movies or for showcasing the original artworks like the Brussels Comic Book Museum.
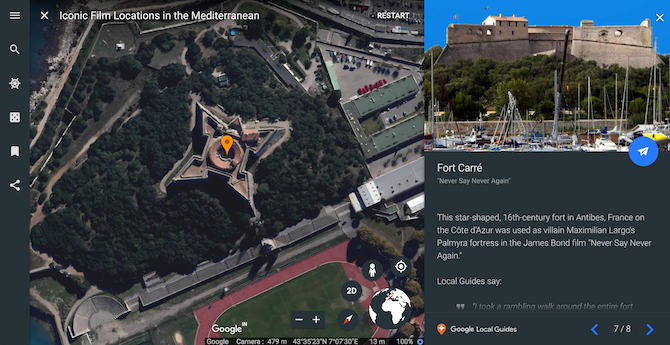
Are you more of a movie buff than a comic book aficionado? Try the Iconic Film Locations in the Mediterranean virtual tour then. Travel to each selected landmark from the Mediterranean where movie scenes have been shot like Fort Carré in Never Say Never Again.
This virtual tour will help you get familiar with the basics of coral reefs. See how these marvelous underwater colonies are formed over millions of years. Each chapter discusses fundamental topics like Coral Reef Diversity, Global Threats to Coral Reefs with video highlights and subaqueous Street View.
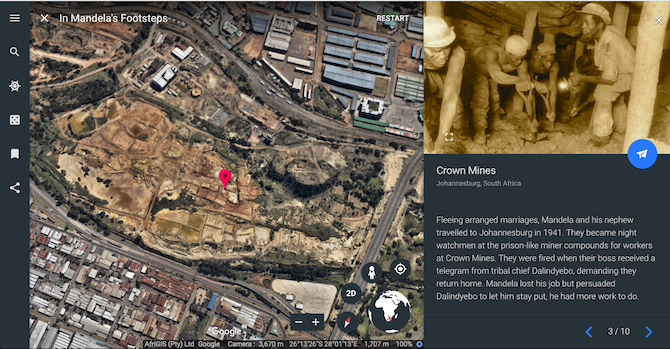
Take a walk through the legendary political leader and former president of South Africa, Nelson Mandela’s road to freedom in this virtual tour. The series highlights places which played a critical role in his life such as the University of Fort Hare which was one of the first to allow non-white people to study, Johannesburg’s Crown Mines where he worked as a night watchman, and more.
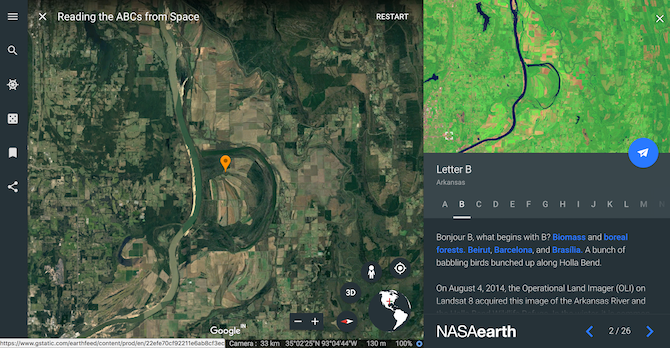
Perhaps, the most intriguing virtual tour available on Google Earth is Reading the ABCs From Space. Developed by NASA, the tour comprises of twenty-six chapters which reveal locations that form an alphabet like a coral reef in the shape of a J or the intersection of two lakes which resembles V.
My personal favorite is the Lunar Crater from India which looks like a Q and was the result of a meteor hit.
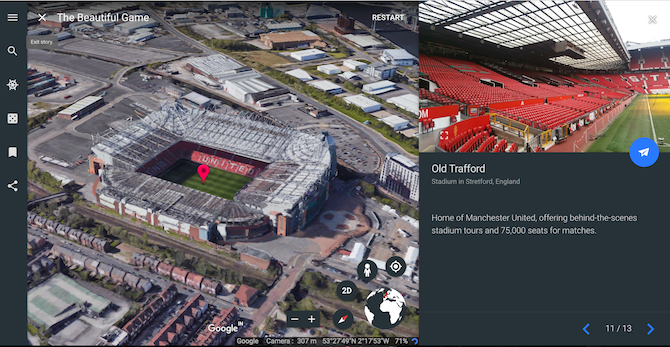
If you’re still in the World Cup spirit, you might want to check out The Beautiful Game. The virtual tour takes you around a bunch of the world’s most unforgettable soccer destinations like Bayern Munich’s 75,000-capacity football ground, Barcelona’s Camp Nou, and of course, Manchester United’s Old Trafford.
Keep the World at Your Fingerprints
We have barely scratched the surface today. You will find them divided into subcategories like Nature, Culture, Sports, and others. It will take you some time to go through all of them. And yes, all of them are entirely free of cost. A reliable and high-bandwidth web connection is a must, though.
Google Earth is an offshoot of Google Maps. So, take some time to understand how Google Maps works as well. It is a fascinating topic.
Google has inducted a new class of startups into the Launchpad Studio accelerator it inaugurated last year; the first group was focused on gleaning new insights from medical data, and this one is about shaking up established financial markets and systems.
Some of the companies are well-known, established businesses — but this isn’t the usual type of accelerator that aims to take a fledgling business and bring it to market. Instead, Google supports the selected companies in the development of a project, generally involving applying machine learning to the space they operate in. They call Studio a “product acceleration program.” (There are regular accelerators under the Launchpad brand as well.)
This year the companies are all more or less in the financial space, offering banking, identity verification, and retail services in locales around the world. Here’s the list, with Google’s descriptions of each:
Alchemy (USA), bridging blockchain and the real world
Axinan (Singapore), providing smart insurance for the digital economy
Aye Finance (India), transforming financing in India
Celo (USA), increasing financial inclusion through a mobile-first cryptocurrency
Frontier Car Group (Germany), investing in the transformation of used-car marketplaces
Go-Jek (Indonesia), improving the welfare and livelihoods of informal sectors
GuiaBolso (Brazil), improving the financial lives of Brazilians
Inclusive (Ghana), verifying identities across Africa
m.Paani (India), (em)powering local retailers and the next billion users in India
Robinhood (USA), democratizing access to financial market
Starling Bank (UK), improving financial health with a 100% mobile-only bank
It’s easy to imagine what interesting patterns or helpful knowledge might emerge from a careful analysis of millions of data points tied to demographics, locations, financial situations, and so on.
Robinhood’s popular stock-trading platform is hardly in need of rescue by Google’s resident experts and mentors, but again the data it has access to is the interesting part. Why not collaborate with those experts to create new product ideas or studies?
Google provides cloud computing resources, access to its stable of tame ML researchers, and continuing support after the 4-month period is over.
Congrats to the startups selected for the program; we’ll keep our ears open for whatever products emerge from their work.
The Justice Department has confirmed that Attorney General Jeff Sessions has expressed a “growing concern” that social media giants may be “hurting competition” and “intentionally stifling” free speech and expression.
The comments come as Facebook chief operating officer Sheryl Sandberg and Twitter chief executive Jack Dorsey gave testimony to the Senate Intelligence Committee on Wednesday, as lawmakers investigate foreign influence campaigns on their platforms.
“The Attorney General has convened a meeting with a number of state attorneys general this month to discuss a growing concern that these companies may be hurting competition and intentionally stifling the free exchange of ideas on their platforms,” said Justice Department spokesman Devin O’Malley.
Neither Facebook nor Twitter immediately responded to a request for comment.
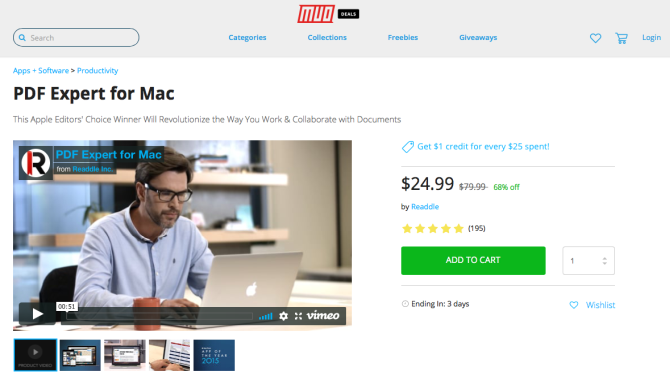
Mac app developers often put their software on sale through the Mac App Store. But all sorts of great apps aren’t offered on the App Store.
Although you may occasionally notice a deal on Facebook or Twitter, there are dedicated sites to help you find Mac apps on sale. We’ll show you eight ways to find discounts on Mac apps not available on the App Store.
MakeUseOf Deals offer a broad selection of deals on electronic gears and gadgets, apps, subscription-based web services, online courses, and design assets. Go to the Deals page, and choose Categories > Apps + Software. You’ll see all the apps, including web apps, running on sale.
You can arrange those deals in different ways. Click the Filter By dropdown menu to narrow the selection choice, or use the Sort By dropdown menu to sort them by best sellers, newest apps, or sales ending soon.
There’s another unique feature, called the Pay What You Want bundle. If you enter an amount less than the average price, you’ll only get a few items from the bundle. Choose the average price to buy the entire bundle.
First-time MUO Deals users can also get an extra 10 percent discount on their first purchase.
Sometimes you find yourself buying a bundle only to get few particular apps. This means you’re stuck with apps you’ll never use.
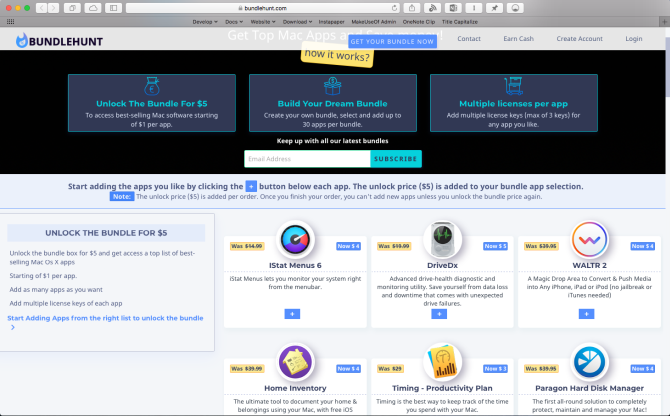
BundleHunt is a bundle site that offers a large selection of Mac apps, with an option to curate app selection yourself to avoid unwanted downloads. You can get those apps at a fixed price. Some apps are as low as $1, with a maximum price of $5.
Start adding the apps you like by clicking the Plus button below each app. In addition to the cost of the individual apps, you’ll have to pay $5 to “unlock” your bundle. Upon your purchase, you’ll get instant access to the license keys for apps you brought. You can even add multiple license keys (limit of three) for any app you like.
BundleHunt also lets you export registration keys as a CSV file. Go to Account > Downloads & License Keys, select your bundle, and click Export License Keys. Then import that file in the password manager of your choice to keep the details safe.
All the apps included in the bundle are directly available from the developer websites. You’ll also get the latest version of every app. You can follow BundleHunt on Twitter or sign up for the newsletter to get the latest updates.
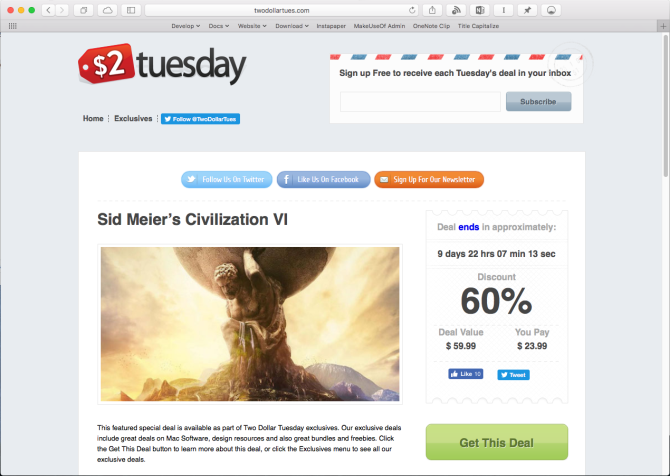
Two Dollar Tuesday helps you discover Mac Apps at significant discounts. Every Tuesday, it features a few apps at a discount ranging from 50-90 percent. It promotes apps both from developer websites and the App Store.
If you find any app useful, click the Get This Deal button to buy that app before the deal expires. You can follow Two Dollar Tuesday on Twitter or subscribe to the newsletter so you never miss a deal.
BitsDuJour is an all-in-one deals website to bring you exclusive deals on Mac apps. It uses the coupon code system to process all the discounts. Click the Get This Deal button to purchase the app directly from the developer website. The discount is available only through this link, and since you’re buying the app directly from the developer, it’s a legal purchase.
The promotions typically last for 24 hours, although this may extend based on demand. Click the app name, and you’ll find every detail about it. You can go through the app description, see screenshots, ask the developer questions about the app or offer, review fine print about the deal, and more.
What makes BitsDuJour unique is the community involvement. You can browse forums, vote for the apps you’d like to see discounted, and check upcoming app discounts. To keep up with the latest updates, follow BitsDuJour on Twitter or add the BitsDuJour RSS feed to your feed reader.
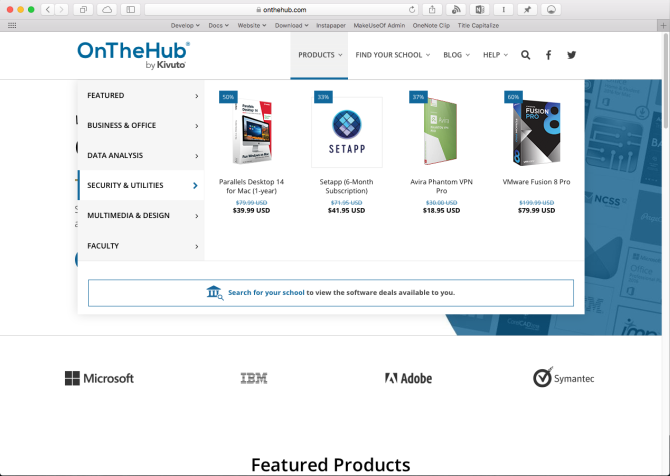
OnTheHub is a premier website for productivity and academic software. It gives discounted or even free software to students and faculties. The discounts range from 50-90 percent.
Software titles include Microsoft Windows 10 for Education (one of the lesser-known Windows 10 versions), Microsoft Office 2016 Professional Edition, IBM SPSS Statistics, Parallels Desktop for Mac, VMware Fusion 8, EndNote X9, Adobe Creative Cloud Suite, Setapp, and more. Use OnTheHub School Search to find out if your school or college is eligible.
Alternatively, visit the OnTheHub eStore, submit valid proof of academic affiliation, and purchase your apps. Your account holds all the information (including registration details) about apps you purchase. OnTheHub regularly posts new articles on its blog; follow OnTheHub on Twitter and contact them if you have any questions.
The idea behind this service is that every student can get a discount on quality Mac apps without hunting though dozens of developer websites. You’ll see all kinds of options, including productivity, utilities, backup, calendar, academic apps, and more. The discounts range from anywhere between 20-50 percent.
The website has five categories: Organize, Enhance, Inspire, Develop, and Achieve. Within each group, you’ll find a dozen apps. Students can claim their discount by sending any one of the following forms of evidence: course acceptance letter, student ID card, or course bill.
Humble Bundle is a distribution platform for selling games, software, ebooks, and other digital assets. Most bundles you see here offer a Pay What You Want system. You’ll need to pay more than the average price to unlock all rewards.
It also offers you great deals on games for both PC and Mac. You can still have a great gaming experience on Mac if you choose the right games and follow specific settings. Check the platform icon and system requirements for information about game compatibility.
If a particular game is not compatible with Mac, you’ll see a Not Available message in red text next to the platform icon. Apart from these bundles, Humble Bundle also offers smaller weekly bundles and daily discounts in the Humble Store. Follow Humble Bundle on Twitter to get the latest updates on deals.
Searching and keeping up-to-date with deals is not easy. To make it more simple and save time, MacBundles offers you a one-stop website to find and consolidate app bundles from many sites in a single place. It features bundles from BundleHunt, Creatable, Parallels, MacUpdate, and many more. Subscribe to the newsletter and get all the latest updates.
Get Premium Mac Apps for One Low Price
While getting apps from app bundles is a great way to save money, they may not always include quality software. You often end up buying a bundle to get one or two apps you want.
If you’re willing to spend $10 per month, you can have access to growing collection of quality Mac apps from different developers through Setapp.
Setapp is a new service from MacPaw that adopts a subscription model for Mac apps. As long as you’re a subscriber, you’ll get periodic updates and new apps. If you find this idea interesting, check out our overview of Setapp. We’ve also covered how to find Mac and iOS App Store discounts.
AnchorFree, a maker of a popular virtual private networking app, has raised $275 million in a new round of funding, the company announced Wednesday.
The Redwood City, Calif.-based app maker’s flagship app Hotspot Shield ranks as one of the most popular VPN apps on the market. The app, based on a freemium model, allows users across the world tunnel their internet connections through AnchorFree’s servers, which masks users’ browsing histories from their internet providers and allows those under oppressive regimes evade state-level censorship.
The funding was led by WndrCo, a holding company focusing on consumer tech businesses, in addition to Accel Partners, 8VC, SignalFire, and Green Bay Ventures, among others.
At today’s Senate Intelligence Committee hearing Twitter CEO Jack Dorsey was asked by vice chair Sen. Mark Warner whether users should have “a right to know” if they are talking to a bot or a human on its platform — to help people better navigate the information they are being exposed to.
Dorsey agreed that “more context” around tweets and accounts is good, but — when pressed by Warner on whether Twitter should have a policy to ID bots vs humans on the platform — he said Twitter is actively considering it, albeit cautioning “as far as we can detect them”.
“We can certainly label and add context to accounts that come through our API,” he continued. “Where it becomes a lot trickier is where automation is actually scripting our website to look like a human actor. So as far as we can label and we can identify these automations we can label them — and I think that is useful context.”
“It’s an idea that we have been considering over the past few months,” he added. “It’s really a question of the implementation — but we are interested in it. And we are going to do something along those lines.”
A bit later in the session, answering questions about fake accounts, Dorsey said Twitter has had more success in identifying inauthentic activity on its platform by using deep learning and machine learning technologies that are focused on identifying “behavioral patterns” — so looking at account behavior across the network — rather than trying to identify where specific accounts are located in real-time.
“We’ve got a lot more leverage out of that in terms of scale vs systems that try and identify fake profiles,” he added.
Alphabet’s decision to decline to send its CEO Larry Page to today’s Senate Intelligence Committee hearing — to answer questions about what social media platforms are doing to thwart foreign influence operations intended to sow political division in the U.S. — has earned it a stinging rebuke from the committee’s vice chair, Sen. Mark Warner.
“I’m deeply disappointed that Google – one of the most influential digital platforms in the world – chose not to send its own top corporate leadership to engage this committee,” said Warner in his opening remarks, after praising Facebook and Twitter for agreeing to send their COO and CEO respectively.
Alphabet offered its SVP of global affairs and chief legal officer, Kent Walker, to testify in front of lawmakers but declined to send CEO Page or Google CEO Sundar Pichai.
Committee chairman, Richard Burr, was slightly less stinging in his opening remarks but also professed himself “disappointed that Google decided against sending the right senior level executive”.
“If the answer is regulation let’s have an honest dialogue about what that looks like. If the key is more resources or legislation that facilitates information sharing and government co-operation let’s get it out there,” he concluded. “If it’s national security policies that punish the kind of information and influence operations that we’re talking about this morning to the point that they aren’t even considered in foreign capitals then let’s acknowledge that. But whatever the answer is we’ve got to do this collaboratively and we’ve got to do this now. That’s our responsibility to the American people.”
Warner said committee members have “difficult questions about structural vulnerabilities on a number of Google’s platforms that we will need answered“, calling out a number of Google products by name and identifying abuse associated with those services.
“From Google Search, which continues to have problems surfacing absurd conspiracies….To YouTube, where Russian-backed disinformation agents promoted hundreds of divisive videos….To Gmail, where state-sponsored operatives attempt countless hacking attempts, Google has an immense responsibility in this space. Given its size and influence, I would have thought the leadership at Google would want to demonstrate how seriously it takes these challenges and to lead this important public discussion.”
We’ve reached out to Google for a response.
Warner concluded his opening remarks with some policy suggestions for regulating social media platforms, saying he wanted to get the companies’ constructive thoughts on issues such as whether platforms should identify bots to their users; whether there’s a public interest in ensuring more anonymized data is available to researchers and academics to help identify potential problems and misuse; why terms of service are “so difficult to find and nearly impossible to read; why US lawmakers shouldn’t adopt ideas such as data portability, data minimization, or first party consent — which are already baked into EU privacy law — and what further accountability there should be related to platforms’ “flawed advertising model”.
Alphabet’s decision to decline to send its CEO Larry Page to today’s Senate Intelligence Committee hearing — to answer questions about what social media platforms are doing to thwart foreign influence operations intended to sow political division in the U.S. — has earned it a stinging rebuke from the committee’s vice chair, Sen. Mark Warner.
“I’m deeply disappointed that Google – one of the most influential digital platforms in the world – chose not to send its own top corporate leadership to engage this committee,” said Warner in his opening remarks, after praising Facebook and Twitter for agreeing to send their COO and CEO respectively.
Alphabet offered its SVP of global affairs and chief legal officer, Kent Walker, to testify in front of lawmakers but declined to send CEO Page or Google CEO Sundar Pichai.
Committee chairman, Richard Burr, was slightly less stinging in his opening remarks but also professed himself “disappointed that Google decided against sending the right senior level executive”.
“If the answer is regulation let’s have an honest dialogue about what that looks like. If the key is more resources or legislation that facilitates information sharing and government co-operation let’s get it out there,” he concluded. “If it’s national security policies that punish the kind of information and influence operations that we’re talking about this morning to the point that they aren’t even considered in foreign capitals then let’s acknowledge that. But whatever the answer is we’ve got to do this collaboratively and we’ve got to do this now. That’s our responsibility to the American people.”
Warner said committee members have “difficult questions about structural vulnerabilities on a number of Google’s platforms that we will need answered“, calling out a number of Google products by name and identifying abuse associated with those services.
“From Google Search, which continues to have problems surfacing absurd conspiracies….To YouTube, where Russian-backed disinformation agents promoted hundreds of divisive videos….To Gmail, where state-sponsored operatives attempt countless hacking attempts, Google has an immense responsibility in this space. Given its size and influence, I would have thought the leadership at Google would want to demonstrate how seriously it takes these challenges and to lead this important public discussion.”
We’ve reached out to Google for a response.
Warner concluded his opening remarks with some policy suggestions for regulating social media platforms, saying he wanted to get the companies’ constructive thoughts on issues such as whether platforms should identify bots to their users; whether there’s a public interest in ensuring more anonymized data is available to researchers and academics to help identify potential problems and misuse; why terms of service are “so difficult to find and nearly impossible to read; why US lawmakers shouldn’t adopt ideas such as data portability, data minimization, or first party consent — which are already baked into EU privacy law — and what further accountability there should be related to platforms’ “flawed advertising model”.
Update: A Google spokesperson sent us its earlier statement — in which it writes:
Over the last 18 months we’ve met with dozens of Committee Members and briefed major Congressional Committees numerous times on our work to prevent foreign interference in US elections. Our SVP of Global Affairs and Chief Legal Officer, who reports directly to our CEO and is responsible for our work in this area, will be in Washington, D.C. on September 5, where he will deliver written testimony, brief Members of Congress on our work, and answer any questions they have. We had informed the Senate Intelligence Committee of this in late July and had understood that he would be an appropriate witness for this hearing.
Like any discipline or culture, the internet has all kinds of terms that are foreign to newcomers. Whether you have trouble understanding the language of the web or have seen a new word popping up and wonder what it means, we’re here to help with a glossary of common internet terms.
We’ve explained some internet slang in the past, so this time, we’ll focus on more technical terms and definitions. Let’s get started!
1. 404
One of the most common errors seen online, a 404 simply means that the page you’re looking for doesn’t exist. Typically, you’ll see this when you click a link to a page that’s no longer available or enter an incorrect address into your browser.
2. Add-Ons (Extensions)
Browser add-ons (in Firefox) or extensions (in Chrome) are small pieces of software that provide extra functionality to your browser. They can introduce huge benefits, but are also potential privacy risks.
It’s important to note that add-ons are different than plugins. Plugins, such as Java and Flash Player, are runtimes to access a specific type of content on a page.
3. Anime
While anime is a catch-all Japanese term for animation, the world outside of Japan uses anime to refer specifically to Japanese animation. Anime often has vivid colors and expressive characters. It’s distinct from manga, the term for Japanese comics.
Archiving is the act of removing data from an active environment but keeping it handy in a secondary location. For example, you might archive some old photos by placing them on a secondary hard drive.
Note that archiving and backing up are different. Backing up makes a copy in case of data loss, while archiving is relocating inactive data.
5. Bandwidth
Bandwidth refers to the maximum throughput of data, often across a network. The higher the bandwidth, the more activity you can process at once.
For example, if you’re streaming Netflix in 4K on your TV while you download huge files on your PC, your online gaming experience will likely suffer. This is because you only have so much bandwidth, and you’re using most of it for streaming and downloading. Once you finish these activities, your bandwidth is freed up for other uses.
6. Blog
A blog is simply a website that posts frequent content updates for visitors. Blogs can be simple spots where one person posts their thoughts using a free service, or complex websites with teams of authors, similar to an online magazine.
All blogs are websites, but not all websites are blogs. You might also hear the term “microblogging”, which combines the convenience of instant messaging with blogging. Services like Twitter have made it easy to post short snippets to your followers instead of more involved blog posts.
Clickbait is a term for content formed or titled in a way that tempts users into clicking it. Usually, clickbait titles use sensational language and promise something amazing if the reader clicks through. Clickbait can also draw out one-sentence pieces of information into an entire article, like in the tweet above.
An example is:
10 Ways Your Computer Is Making You Sick. #7 Is Insane!
People often use the term to refer to any article that they don’t like, which isn’t correct.
8. Cloud
The “cloud” is a common term for a set of someone else’s servers devoted to an internet service. Dropbox, Gmail, and Office Online are all cloud services because remote servers handle the work instead of your PC.
9. Cookie
A cookie is a small piece of information on your computer that websites use to track your data between sessions. They’re what let you add an item to your cart and return later, or check the Remember me box so you don’t have to sign in every time.
10. Crowdfunding
Crowdfunding is the act of raising money for a new project through donations online. This relies on receiving a small amount of money each from many people. Well-known crowdfunding websites include Kickstarter and GoFundMe.
11. Dark Web
The dark web is a name for websites that you can’t access without special software. These sites aren’t indexed by Google, and are often criminal, vile, or otherwise dangerous.
Doxing refers to digging up someone’s private information and publishing it on the internet (usually with malicious intent). This obviously opens the person up to danger, sometimes requiring them to move.
13. Embed
Embedding is simply integrating content from one source into another online. A YouTube video or Spotify playlist linked partway through a MakeUseOf article is embedded.
14. Encryption
In simple terms, encryption is the act of scrambling plain text so it’s unreadable to everyone except the intended recipient. Encryption protects your information when you pay online and in many other ways. Check out our guide to encryption for more information.
15. Firewall
A firewall is a type of security software that restricts the network traffic coming in and out of your device. It shields your PC or phone from dangerous packets before they can harm it.
16. Godwin’s Law
Godwin’s law is an old internet maxim that states as an online discussion progresses, the chances increase that someone will bring up a comparison to Hitler. While it sounds silly, it’s fascinating to see it in action on forums, Facebook comment conversations, and similar.
17. Hashtag
A hashtag is a simple form of metadata for posts on social media sites, particularly Twitter and Instagram. It allows you to mark your post so that others can easily find it and others about a specific topic.
In general, a hotspot refers to a device or location where you can access the internet through Wi-Fi.
Hotspot can also refer to the function of smartphones to broadcast their own Wi-Fi networks using mobile data. Further still, portable hotspots are dedicated devices sold by cell companies that provide Wi-Fi anywhere.
19. HTTP
HTTP stands for Hypertext Transfer Protocol and is the foundation of today’s web. It provides a procedure for a web browser to request information from a server hosting a website, then display that information to you.
HTTPS, the secure version of HTTP, protects you by encrypting your session.
20. Internet of Things
The Internet of Things (IoT) is the name for the expansion of internet connectivity to everyday devices that were previously “dumb.” This includes lights, refrigerators, and thermostats. Unlike computers and phones that humans operate, IoT devices can communicate without our intervention.
An IP address is a number assigned to every device that connects to the internet. Each device on your home network has an internal IP address that only your home devices can see. Meanwhile, your entire network has one external IP address that the internet at large views.
22. Lurk
Lurking refers to people who watch an online community, but don’t participate themselves. This might be someone who uses Twitter without an account or checks Reddit every day but never votes or comments.
As it turns out, lurkers are the majority as explained by the 1% rule. This states that only 1% of users in an online community actually create new content.
23. Malware
Malware, a blend of “malicious” and “software”, is a catch-all term for dangerous software. Viruses, Trojans, ransomware, spyware, adware, and more are all under its umbrella.
24. Online/Offline
This one’s simple—online means that your computer, phone, or other device is connected to the internet. Conversely, if you’re offline, you don’t have a connection and are thus cut off from the rest of the online world.
25. Paywall
A paywall refers to blocking online content unless you pay for it. If websites can’t cover their costs via advertising or other methods, they often turn to paywalls. Some websites use a soft paywall, where you can view a few articles for free and have to pay afterward. The New York Times is an example.
26. Phishing
Phishing is the practice of tricking people by disguising yourself as a trusted entity in order to steal their personal information. This often comes in the form of phony emails from a “bank” asking you to confirm your information.
SEO, or search engine optimization, is the practice of improving your website’s standing in search engines (almost always Google). It involves a variety of internal and external factors, all with the end goal of getting your content to more people.
28. Spam
Spam is the name for unwanted messages online. Email spam is a common form, but spam can also come in repeated messages on forums, “spamdexing” search engine results, junk pages on social media, and various other methods.
29. Sticky Content
In an online forum, sticky content (or “stickied”) refers to a post that the moderators pin to the top of the board. While boards are usually sorted in chronological order, a sticky thread is especially important, containing FAQs or timely information.
Sticky content can also refer to parts of a website intended to keep users coming back.
30. Troll
A troll is someone who intentionally starts arguments or otherwise upsets people online. Typically, trolls do this with off-topic or provocative messages designed to get an emotional response.
31. URL
A URL, or uniform resource locator, is a reference to content somewhere on the web. Entering a URL into your browser’s address bar navigates to that page. Right now, that shows the URL for this article.
32. Wiki
A wiki is a type of website where users collaborate to collect and improve information. The best-known example of this is Wikipedia, but there are thousands of wikis for all sorts of communities. You can also create your own wiki around whatever topic you’d like.
Now You’re in the Know
We’ve covered over 30 online terms that every user should know. Hopefully, you now feel more confident about internet lingo and are ready to converse on the web!
Ahead of Facebook COO Sheryl Sandberg testifying before Congress later today, where she will be questioned alongside Twitter CEO Jack Dorsey as US lawmakers wrestle with how to regulate social media platforms (and even just to get bums on seats, given Google’s Larry Page declined to attend), the Pew Research Center has published new research suggesting Americans have become more cautious and critical in their use of Facebook over the past year.
It’s certainly been a year of scandals for the social media behemoth, which started 2018 already on the back foot already in the wake of Kremlin-backed election interference revelations — and with Mark Zuckerberg saying his annual personal mission for the new year would be the embarrassingly unfun challenge of “fixing Facebook”.
Since then things have only got worse, with a major global scandal kicking off in March after fresh revelations about the Cambridge Analytica data misuse sandal snowballed and went on to drag all sorts of other data malfeasance skeletons out of Facebook’s closet.
‘Locking down the platform’ is the new ‘closing the stable door after the horse has bolted’.
So if US Facebook users are changing how they use the platform as a result of all this scandalabra it’s hardly surprising (or only if you believe the lie Zuckerberg has fenced for years that people don’t care about privacy).
Pew sees evidence of a change in US users’ relationship with the service, noting that many users have adjusted privacy settings (52%); taken a break from Facebook of at least a few weeks (42%); while around a quarter (26%) said they had deleted the Facebook app from their cellphone.
All told, it said that almost three-quarters (74%) of Facebook users told it they have taken at least one of these three actions in the past year.
Most worryingly for Facebook, it found differences in the reaction of users depending on their age — with younger users (18 to 29) by far the most likely to say they had deleted the Facebook app in the past year.
So privacy alive and kicking among the young then — not, er, dead.
Similarly, Pew found that older users are much less likely to say they have adjusted their Facebook privacy settings in the past 12 months: Only a third of users 65 and older have done this vs a full 64% of younger users.
It also found that only around one-in-ten Facebook users (9%) have downloaded the personal data about them available on Facebook — a possibility which was given extra publicity by Zuckerberg’s testimony to US lawmakers.
Despite this group representing a relatively small slice as a share of the Facebook population, Pew couches these users as “highly privacy-conscious” — saying roughly half (47%) of the users who have downloaded their personal data from Facebook have deleted the app from their cellphone, while 79% have elected to adjust their privacy settings.
Ergo it looks like awareness of data risks strengthens pro-privacy behavior among users. Who’d have thought it?!
Pew’s study was carried out between May 29 and June 11, 2018 — so well after the Cambridge Analytica scandal had snowballed into a major PR crisis for Facebook — with the research firm polling more than 4,500 respondents
A separate Pew study, also conducted at the same time and published today, suggests many US users don’t understand how Facebook’s News Feed works.
The survey found that “notable shares” of Facebook users ages 18 and older lack a clear understanding of how the site’s News Feed operates; feel they have little control over what appears there; and have not actively tried to influence the content the feed delivers to them.
When asked whether they understand why certain posts but not others are included in their news feed, around half of U.S. adults who use Facebook (53%) say they do not — with a fifth (20%) saying they do not understand the feed at all well.
Older users are especially likely to say they do not understand the workings of the News Feed: Just 38% of Facebook users ages 50 and older say they have a good understanding of why certain posts are included in it vs 59% of users ages 18 to 29.
While Facebook offers some tools for users to control what they see in the Feed, such as by giving priority to certain people or hiding posts from others, Pew found that just 14% of Facebook users believe ordinary users have a lot of control over the content that appears there – and twice that share (28%) said they felt they have no control.
Older Facebook users in particular feel they have little agency in this regard: Some 37% of Facebook users 50 and older think users have no control over their News Feed, roughly double the share among users ages 18 to 49 (20%), Pew also found.
The existence of user controls on Facebook’s platform was a factor that Zuckerberg deferred to multiple times during his testimony to lawmakers earlier this year, claiming for example that Facebook users have “complete control” over how their information is used as a result of the settings the platform offers them.
Whatever the truth of the substance of that claim, many Facebook users clearly feel they have little control over what they are exposed to on the service — which in turn undermines the company’s claims that it puts its users in the driving seat when it comes to data (be that how their own data is used, or what other data the service exposes them to).
The lack of transparency around algorithmically controlled content platforms is likely to be a key theme in the Senate Select Intelligence Committee’s questioning of the social media execs later today. (More for how to watch the hearings here.)
We’ve reached out to Facebook for comment on Pew’s research.