This week, Facebook invited a small group of journalists — which didn’t include TechCrunch — to look at the “war room” it has set up in Dublin, Ireland, to help monitor its products for election-related content that violates its policies. (“Time and space constraints” limited the numbers, a spokesperson told us when he asked why we weren’t invited.)
Facebook announced it would be setting up this Dublin hub — which will bring together data scientists, researchers, legal and community team members, and others in the organization to tackle issues like fake news, hate speech and voter suppression — back in January. The company has said it has nearly 40 teams working on elections across its family of apps, without breaking out the number of staff it has dedicated to countering political disinformation.
We have been told that there would be “no news items” during the closed tour — which, despite that, is “under embargo” until Sunday — beyond what Facebook and its executives discussed last Friday in a press conference about its European election preparations.
The tour looks to be a direct copy-paste of the one Facebook held to show off its US election “war room” last year, which it did invite us on. (In that case it was forced to claim it had not disbanded the room soon after heavily PR’ing its existence — saying the monitoring hub would be used again for future elections.)
We understand — via a non-Facebook source — that several broadcast journalists were among the invites to its Dublin “war room”. So expect to see a few gauzy inside views at the end of the weekend, as Facebook’s PR machine spins up a gear ahead of the vote to elect the next European Parliament later this month.
It’s clearly hoping shots of serious-looking Facebook employees crowded around banks of monitors will play well on camera and help influence public opinion that it’s delivering an even social media playing field for the EU parliament election. The European Commission is also keeping a close watch on how platforms handle political disinformation before a key vote.
But with the pan-EU elections set to start May 23, and a general election already held in Spain last month, we believe the lack of new developments to secure EU elections is very much to the company’s discredit.
The EU parliament elections are now a mere three weeks away, and there are a lot of unresolved questions and issues Facebook has yet to address. Yet we’re told the attending journalists were once again not allowed to put any questions to the fresh-faced Facebook employees staffing the “war room”.
Ahead of the looming batch of Sunday evening ‘war room tour’ news reports, which Facebook will be hoping contain its “five pillars of countering disinformation” talking points, we’ve compiled a run down of some key concerns and complications flowing from the company’s still highly centralized oversight of political campaigning on its platform — even as it seeks to gloss over how much dubious stuff keeps falling through the cracks.
Worthwhile counterpoints to another highly managed Facebook “election security” PR tour.
No overview of political ads in most EU markets
Since political disinformation created an existential nightmare for Facebook’s ad business with the revelations of Kremlin-backed propaganda targeting the 2016 US presidential election, the company has vowed to deliver transparency — via the launch of a searchable political ad archive for ads running across its products.
The Facebook Ad Library now shines a narrow beam of light into the murky world of political advertising. Before this, each Facebook user could only see the propaganda targeted specifically at them. Now, such ads stick around in its searchable repository for seven years. This is a major step up on total obscurity. (Obscurity that Facebook isn’t wholly keen to lift the lid on, we should add; Its political data releases to researchers so far haven’t gone back before 2017.)
However, in its current form, in the vast majority of markets, the Ad Library makes the user do all the leg work — running searches manually to try to understand and quantify how Facebook’s platform is being used to spread political messages intended to influence voters.
Facebook does also offer an Ad Library Report — a downloadable weekly summary of ads viewed and highest spending advertisers. But it only offers this in four countries globally right now: the US, India, Israel and the UK.
It has said it intends to ship an update to the reports in mid-May. But it’s not clear whether that will make them available in every EU country. (Mid-May would also be pretty late for elections that start May 23.)
So while the UK report makes clear that the new ‘Brexit Party’ is now a leading spender ahead of the EU election, what about the other 27 members of the bloc? Don’t they deserve an overview too?
A spokesperson we talked to about this week’s closed briefing said Facebook had no updates on expanding Ad Library Reports to more countries, in Europe or otherwise.
So, as it stands, the vast majority of EU citizens are missing out on meaningful reports that could help them understand which political advertisers are trying to reach them and how much they’re spending.
Which brings us to…
Facebook’s Ad Archive API is far too limited
In another positive step Facebook has launched an API for the ad archive that developers and researchers can use to query the data. However, as we reported earlier this week, many respected researchers have voiced disappointed with what it’s offering so far — saying the rate-limited API is not nearly open or accessible enough to get a complete picture of all ads running on its platform.
Following this criticism, Facebook’s director of product, Rob Leathern, tweeted a response, saying the API would improve. “With a new undertaking, we’re committed to feedback & want to improve in a privacy-safe way,” he wrote.
The question is when will researchers have a fit-for-purpose tool to understand how political propaganda is flowing over Facebook’s platform? Apparently not in time for the EU elections, either: We asked about this on Thursday and were pointed to Leathern’s tweets as the only update.
This issue is compounded by Facebook also restricting the ability of political transparency campaigners — such as the UK group WhoTargetsMe and US investigative journalism site ProPublica — to monitor ads via browser plug-ins, as the Guardian reported in January.
The net effect is that Facebook is making life hard for civil society groups and public interest researchers to study the flow of political messaging on its platform to try to quantify democratic impacts, and offering only a highly managed level of access to ad data that falls far short of the “political ads transparency” Facebook’s PR has been loudly trumpeting since 2017.
Ad loopholes remain ripe for exploiting
Facebook’s Ad Library includes data on political ads that were active on its platform but subsequently got pulled (made “inactive” in its parlance) because they broke its disclosure rules.
There are multiple examples of inactive ads for the Spanish far right party Vox visible in Facebook’s Ad Library that were pulled for running without the required disclaimer label, for example.
“After the ad started running, we determined that the ad was related to politics and issues of national importance and required the label. The ad was taken down,” runs the standard explainer Facebook offers if you click on the little ‘i’ next to an observation that “this ad ran without a disclaimer”.
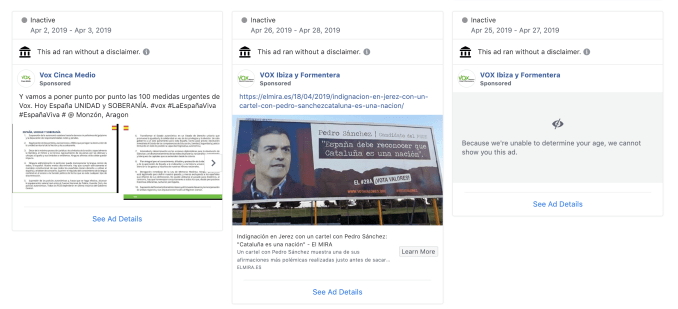 What is not at all clear is how quickly Facebook acted to removed rule-breaking political ads.
What is not at all clear is how quickly Facebook acted to removed rule-breaking political ads.
It is possible to click on each individual ad to get some additional details. Here Facebook provides a per ad breakdown of impressions; genders, ages, and regional locations of the people who saw the ad; and how much was spent on it.
But all those clicks don’t scale. So it’s not possible to get an overview of how effectively Facebook is handling political ad rule breakers. Unless, well, you literally go in clicking and counting on each and every ad…
There is then also the wider question of whether a political advertiser that is found to be systematically breaking Facebook rules should be allowed to keep running ads on its platform.
Because if Facebook does allow that to happen there’s a pretty obvious (and massive) workaround for its disclosure rules: Bad faith political advertisers could simply keep submitting fresh ads after the last batch got taken down.
We were, for instance, able to find inactive Vox ads taken down for lacking a disclaimer that had still been able to rack up thousands — and even tens of thousands — of impressions in the time they were still active.
Facebook needs to be much clearer about how it handles systematic rule breakers.
Definition of political issue ads is still opaque
Facebook currently requires that all political advertisers in the EU go through its authorization process in the country where ads are being delivered if they relate to the European Parliamentary elections, as a step to try and prevent foreign interference.
This means it asks political advertisers to submit documents and runs technical checks to confirm their identity and location. Though it noted, on last week’s call, that it cannot guarantee this ID system cannot be circumvented. (As it was last year when UK journalists were able to successfully place ads paid for by ‘Cambridge Analytica’.)
One other big potential workaround is the question of what is a political ad? And what is an issue ad?
Facebook says these types of ads on Facebook and Instagram in the EU “must now be clearly labeled, including a paid-for-by disclosure from the advertiser at the top of the ad” — so users can see who is paying for the ads and, if there’s a business or organization behind it, their contact details, plus some disclosure about who, if anyone, saw the ads.
But the big question is how is Facebook defining political and issue ads across Europe?
While political ads might seem fairly easy to categorize — assuming they’re attached to registered political parties and candidates, issues are a whole lot more subjective.
Currently Facebook defines issue ads as those relating to “any national legislative issue of public importance in any place where the ad is being run.” It says it worked with EU barometer, YouGov and other third parties to develop an initial list of key issues — examples for Europe include immigration, civil and social rights, political values, security and foreign policy, the economy and environmental politics — that it will “refine… over time.”
Again specifics on when and how that will be refined are not clear. Yet ads that Facebook does not deem political/issue ads will slip right under its radar. They won’t be included in the Ad Library; they won’t be searchable; but they will be able to influence Facebook users under the perfect cover of its commercial ad platform — as before.
So if any maliciously minded propaganda slips through Facebook’s net, because the company decides it’s a non-political issue, it will once again leave no auditable trace.
In recent years the company has also had a habit of announcing major takedowns of what it badges “fake accounts” ahead of major votes. But again voters have to take it on trust that Facebook is getting those judgement calls right.
Facebook continues to bar pan-EU campaigns
On the flip side of weeding out non-transparent political propaganda and/or political disinformation, Facebook is currently blocking the free flow of legal pan-EU political campaigning on its platform.
This issue first came to light several weeks ago, when it emerged that European officials had written to Nick Clegg (Facebook’s vice president of global affairs) to point out that its current rules — i.e. that require those campaigning via Facebook ads to have a registered office in the country where the ad is running — run counter to the pan-European nature of this particular election.
It means EU institutions are in the strange position of not being able to run Facebook ads for their own pan-EU election everywhere across the region. “This runs counter to the nature of EU institutions. By definition, our constituency is multinational and our target audience are in all EU countries and beyond,” the EU’s most senior civil servants pointed out in a letter to the company last month.
This issue impacts not just EU institutions and organizations advocating for particular policies and candidates across EU borders, but even NGOs wanting to run vanilla “get out the vote” campaigns Europe-wide — leading to a number to accuse Facebook of breaching their electoral rights and freedoms.
Facebook claimed last week that the ball is effectively in the regulators’ court on this issue — saying it’s open to making the changes but has to get their agreement to do so. A spokesperson confirmed to us that there is no update to that situation, either.
Of course the company may be trying to err on the side of caution, to prevent bad actors being able to interfere with the vote across Europe. But at what cost to democratic freedoms?
What about fake news spreading on WhatsApp?
Facebook’s ‘election security’ initiatives have focused on political and/or politically charged ads running across its products. But there’s no shortage of political disinformation flowing unchecked across its platforms as user uploaded ‘content’.
On the Facebook-owned messaging app WhatsApp, which is hugely popular in some European markets, the presence of end-to-end encryption further complicates this issue by providing a cloak for the spread of political propaganda that’s not being regulated by Facebook.
In a recent study of political messages spread via WhatsApp ahead of last month’s general election in Spain, the campaign group Avaaz dubbed it “social media’s dark web” — claiming the app had been “flooded with lies and hate”.
“Posts range from fake news about Prime Minister Pedro Sánchez signing a secret deal for Catalan independence to conspiracy theories about migrants receiving big cash payouts, propaganda against gay people and an endless flood of hateful, sexist, racist memes and outright lies,” it wrote.
Avaaz compiled this snapshot of politically charged messages and memes being shared on Spanish WhatsApp by co-opting 5,833 local members to forward election-related content that they deemed false, misleading or hateful.
It says it received a total of 2,461 submissions — which is of course just a tiny, tiny fraction of the stuff being shared in WhatsApp groups and chats. Which makes this app the elephant in Facebook’s election ‘war room’.
What exactly is a war room anyway?
Facebook has said its Dublin Elections Operation Center — to give it its official title — is “focused on the EU elections”, while also suggesting it will plug into a network of global teams “to better coordinate in real time across regions and with our headquarters in California [and] accelerate our rapid response times to fight bad actors and bad content”.
But we’re concerned Facebook is sending out mixed — and potentially misleading — messages about how its election-focused resources are being allocated.
Our (non-Facebook) source told us the 40-odd staffers in the Dublin hub during the press tour were simultaneously looking at the Indian elections. If that’s the case, it does not sound entirely “focused” on either the EU or India’s elections.
Facebook’s eponymous platform has 2.375 billion monthly active users globally, with some 384 million MAUs in Europe. That’s more users than in the US (243M MAUs). Though Europe is Facebook’s second-biggest market in terms of revenues after the US. Last quarter, it pulled in $3.65BN in sales for Facebook (versus $7.3BN for the US) out of $15BN overall.
Apart from any kind of moral or legal pressure that Facebook might have for running a more responsible platform when it comes to supporting democratic processes, these numbers underscore the business imperative that it has to get this sorted out in Europe in a better way.
Having a “war room” may sound like a start, but unfortunately Facebook is presenting it as an end in itself. And its foot-dragging on all of the bigger issues that need tackling, in effect, means the war will continue to drag on.
 Read Full Article
Read Full Article

















 Tumblr could also be repurposed into a “your Internet homepage” platform. Most social networks are so desperate to keep users on their apps that they restrict or deemphasize the ability to promote your other web presences. They also often focus on a narrow set of content types like photos and videos on Instagram. This leaves users who don’t have their own dedicated websites without a central hub where they can freely express their identity and link to profiles elsewhere. This is a huge opportunity for Tumblr, which has already established itself an open-ended self-expression platform open to a variety of content formats.
Tumblr could also be repurposed into a “your Internet homepage” platform. Most social networks are so desperate to keep users on their apps that they restrict or deemphasize the ability to promote your other web presences. They also often focus on a narrow set of content types like photos and videos on Instagram. This leaves users who don’t have their own dedicated websites without a central hub where they can freely express their identity and link to profiles elsewhere. This is a huge opportunity for Tumblr, which has already established itself an open-ended self-expression platform open to a variety of content formats.










{kind=link}