If you need a portable Mac, you buy a MacBook. If you want the most powerful Mac experience, you buy an iMac—right?
Deciding between a desktop and a laptop isn’t quite as simple as you might think. We have to balance our expectations, real-world requirements, and a realistic budget before taking the plunge.
So we’ve done the agonizing for you. Here’s how two of Apple’s flagship machines stack up and a guide to deciding whether a MacBook or an iMac would be better suited to your needs.
Comparing MacBook vs. iMac
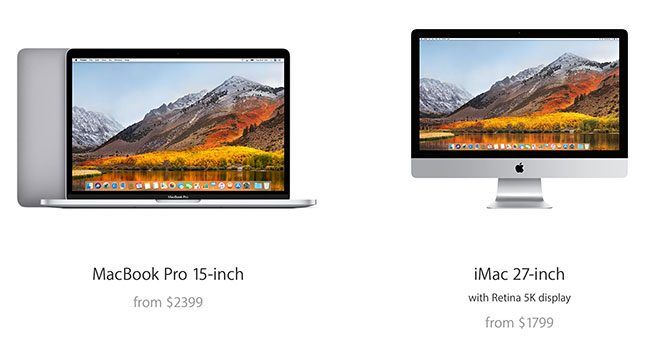
For the purpose of this comparison, we’ll look at the top-end 27-inch iMac model and its closest competitor, the fastest 15-inch MacBook Pro. You’ll likely have your own wishlist, but this comparison is fairly representative of the differences between the models whatever your budget.

Even at this stage, it’s worth thinking about the lifespan of the product. Of the many reasons why people buy Macs, hardware reliability and longevity is perhaps the most important. Make sure whatever you choose will fit the bill for a few years. This is especially true when it comes to storage capacity, since Apple’s machines are less upgradeable than ever before.

Now let’s take a look at each aspect of Apple’s computers by directly comparing hardware, and ultimately value for money.
MacBook vs. iMac: CPU and RAM
There once was a time when the desktop variants would run away with the show here. But thanks to the ever-shrinking silicon chip, it’s far less clear-cut than it once was. Mobile chips need to be efficient, which means you’re unlikely to see comparable clock speeds. This doesn’t necessarily translate into a black and white performance deficit, though.
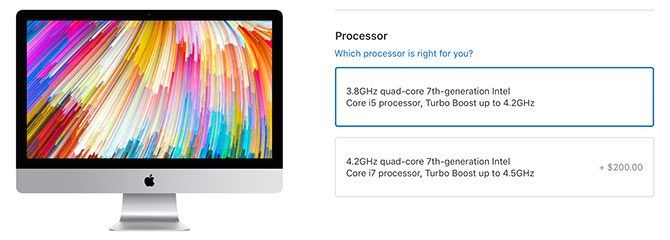
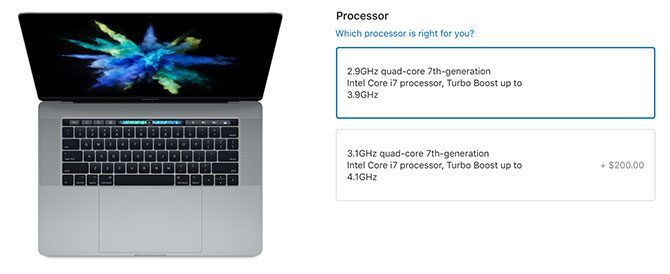
The top-tier 27-inch iMac comes with a 3.8GHz Intel Core i5 processor. You can upgrade this to an i7 4.2GHz processor for an extra $200. The MacBook Pro has an Intel Core i7 processor that tops out at 2.9GHz, with an upgrade to the 3.1GHz model available for another $200.
In terms of processing power, while the iMac has the advantage due to higher clock speeds, you’re unlikely to notice the difference in daily use. When it comes to RAM, it’s a similar state of affairs.
The top-tier MacBook Pro comes with 16GB of RAM onboard, compared to the iMac’s 8GB. You can upgrade the iMac to 16GB ($200), 32GB ($400), or 64GB ($1,200). However, you can’t upgrade a MacBook Pro beyond 16GB.
But the iMac has another trick up its sleeve: a slot at the back of the unit which allows you to upgrade the RAM yourself. This is not possible on the MacBook Pro, but it’s a nice option for iMac users who want to save some money today and upgrade in the future.
Conclusion: Processing power is comparable, though the iMac just tips it which makes the MacBook Pro even more impressive. User-expandable memory and more options at checkout further give the iMac the edge here.
MacBook vs. iMac: GPU and Display
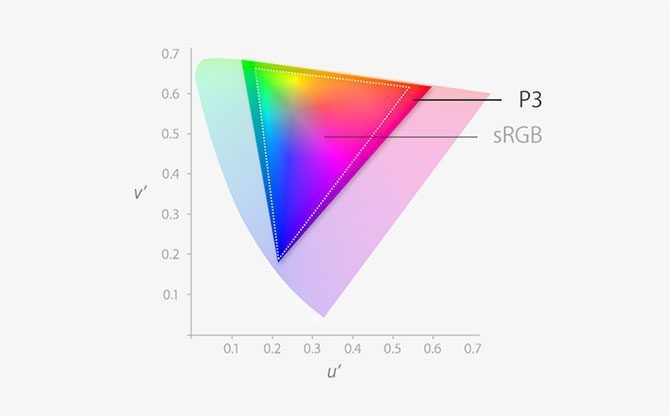
Both the MacBook Pro and iMac have comparable displays. Each is Retina quality, which means the pixel density is high enough that you can’t make out individual pixels. Both have a brightness of 500 nits, and both use the P3 wide color gamut offering 25 percent more colors compared to standard RGB.
The most obvious difference is size, with a top-end iMac coming in at 27-inch compared to the MacBook Pro at 15-inch. And while the MacBook Pro manages a native resolution of 2880×1800, the iMac has a native 5K display at a jaw-dropping resolution of 5120×2880.
Both will make your videos and photos pop and the hours you spend staring at your screen more pleasant. There really is something to be said for the iMac’s massive 5K screen, though you’ll need to sacrifice portability for the privilege.
Powering those displays is no small feat, which is why Apple opted for dedicated Radeon Pro graphics chips from AMD for both models. The MacBook Pro puts up a good fight with its Radeon Pro 560 and 4GB of dedicated VRAM, but it comes up short against the Radeon Pro 580 and its 8GB of VRAM.

You’re certainly not going to see double the performance on the iMac, but there’s no mistaking the fact that the best visual performance is found on the desktop. This is further compounded by the heat generated by GPUs under load, which is far more noticeable on a laptop than it is on a desktop.
That added heat might limit your use of the MacBook under extreme load. If you’re going to stress the GPU regularly with lengthy video editing or gaming sessions, the iMac will provide a more pleasant base of operation. You’ll also have a lot more screen real estate at your disposal.
Conclusion: The MacBook Pro’s top-tier discrete graphics chips are a force to be reckoned with, but the iMac is still faster (and cooler).
MacBook vs. iMac: Storage, SSDs, and Fusion Drive
Here’s where the comparison starts to get really interesting, since the MacBook range led the SSD revolution many years ago with the arrival of the MacBook Air. SSDs (solid-state drives) are storage devices that use memory chips rather than moving parts to store data. This results in much faster read and write times, and they’re a lot tougher.
Every MacBook, MacBook Air, and MacBook Pro comes with an SSD. Most start at 256GB, but you can still find the odd 128GB option around. By comparison, all iMac models come with a Fusion Drive.
Apple’s Fusion Drive is two drives—an SSD and a standard spinning HDD—that appear as a single volume. Core system files and often-used resources reside on the SSD for speed, while documents, media, and long-term storage defaults to the slower HDD.
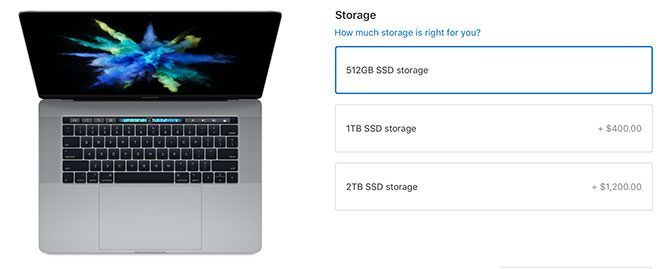
The SSD is faster than the Fusion Drive, but SSDs are also more limited in space. This is why the top-tier MacBook Pro comes with 512GB, and the top-tier iMac comes with 2TB. You can upgrade that MacBook to a 1TB SSD for an additional $400, and you can make the same swap in your iMac for $600.
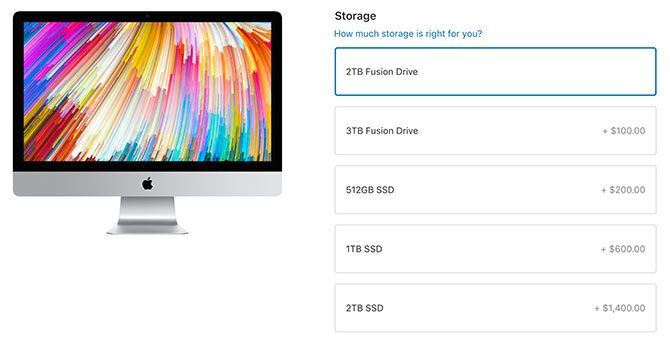
Conclusion: You’ll get more space for your money in an iMac, but it won’t be as fast as the MacBook’s all-SSD approach. If money is no object, you can upgrade both models to a 2TB SSD and laugh all the way home.
It comes down to performance, and the tradeoff you make between convenience and speed. One word of advice: always buy more storage than you think you need.
MacBook vs. iMac: Ports and Portability
If you’ve followed Apple’s hardware decisions of late, you’ll know that the current generation MacBook has fewer ports than any that came before it. Apple decided to strip all but a stereo output and four USB-C ports (capable of USB 3.1 gen 2 and Thunderbolt 3) from the MacBook Pro.

This means you’ll need to rely on adapters and docks if you want to use regular USB type-A connectors, drive an HDMI monitor, plug in a memory card, or connect to a wired network. The new MacBook Pro is even powered via USB-C, with an 87W USB-C power adapter included in the box.
Conversely, the iMac has a port for almost anything. You’ll get two of those fancy USB-C ports that can handle USB 3.1 gen 2 and Thunderbolt 3. You’ll also get four regular USB 3.0 type-A connectors, for all your old hard drives and peripherals.
Then there’s an SDXC card slot on the back, for connecting SD, SDHC, SDXC and microSD (via adapters) directly to your Mac. The iMac even delivers a gigabit Ethernet port, something the MacBook range dropped years ago.

The iMac is also compatible with the same adapters and docks, enabling HDMI and DVI out, or compatibility with Mini DisplayPort and Thunderbolt 2 devices with an adapter. You won’t have to carry this adapter with you either, since your iMac lives on a desk.
Conclusion: The MacBook drops the ball in this department, with its stubborn USB-C approach. As for the iMac, we’re shocked Apple still builds a computer with an Ethernet port!
MacBook vs. iMac: Everything Else
There are a few other areas you might not consider when shopping, and though they’re not deal-breakers (to us), they’re still worth highlighting.
Keyboard
While the MacBook Pro has a built-in keyboard, the iMac comes with Apple’s Magic Keyboard. You can also opt to ditch these and plug in any keyboard you want, something that makes more sense on the iMac.

Some users have reported issues with Apple’s “butterfly” key mechanism on the latest MacBook models. There have been reports of broken keys that have prompted several class-action lawsuits, as well as the keyboard having a different “feel” to previous Apple keyboards.
You’ll probably want to try out the MacBook before you buy if you plan to do a lot of typing (and even if you’re not, since a dud key compromises the entire laptop’s purpose).
Mice, Trackpads, and Touch Gestures
Apple has designed macOS with a number of touch-based gestures in mind. These include two-finger scrolling, swipes from left to right to change between desktop spaces, and quick reveal gestures for running apps and the desktop. macOS is better with a trackpad than it is with a mouse.

The MacBook Pro has a giant trackpad front and center. Force Touch means you can press harder to access a third context-dependent input, just like 3D Touch on the iPhone.
The iMac comes with a Magic Mouse 2, probably because Apple has a big dusty warehouse full of them. If you want the best macOS experience, you’ll need to upgrade to a Magic Trackpad 2 for $50 at checkout.
Touch Bar and Touch ID
The Touch Bar and Touch ID fingerprint scanner are both present (and non-negotiable) on the top-tier MacBook Pro models. This replaces the function keys with a touch-sensitive OLED panel. The panel adapts to whatever you’re doing and shows you relevant app controls, emoji, and traditional media key functions.
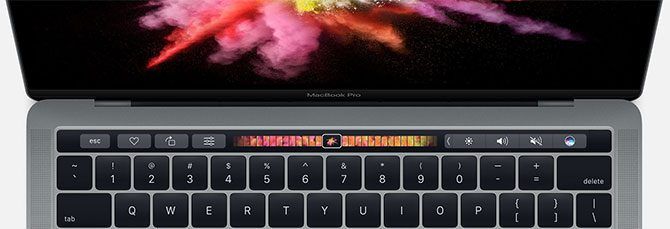
Touch ID is a fingerprint scanner that works just like Touch ID on iOS. You can use your fingerprint to store login credentials, unlock your Mac, and generally speed up daily authorization events. It’s a great convenience, but probably won’t tip your decision either way.
Some users have complained that the Touch Bar is a gimmick that doesn’t really solve any problems. If you feel the same you can disable the Touch Bar entirely, though you’ll have to live with touch-based function keys.
MacBook vs. iMac: Which One Should You Get?
A top-of-the-line iMac is cheaper than a comparable MacBook Pro. It packs a marginally faster processor, better graphics capabilities, a bigger screen, more storage space, and an array of ports a MacBook owner could only dream of. It lacks the 16GB of RAM, but it’s got a port that you can use to upgrade it yourself.
But the top-end MacBook Pro isn’t a weak option. You’ve got a strong Core i7 processor, a powerful GPU that can handle 4K video editing, a blisteringly fast SSD on every model, and that all-important portable form factor. Ultimately though, you’ll pay more for a less capable machine compared to the iMac.
For pricing, Apple’s best base MacBook Pro (without any upgrades) costs $2,799 compared to $2,299 for a top-end base iMac. When you’re paying $500 more for a less capable machine, you might want to ask yourself: do you really need all that power in a portable machine? Or is portability worth the premium to you?
If you need as much power in the field as possible, then the MacBook Pro is your best bet at this stage. Just make sure you opt for a large enough SSD to see you through to your next upgrade.
But if like me, you’re replacing an old MacBook, you might want to opt for the iMac. You can make your old Mac feel like new, then use it as a light mobile office of sorts. Offload your resource-intensive tasks to the iMac at home, and you’ve got the best of both worlds.
Read the full article: MacBook vs. iMac: A Comparison Guide to Help You Decide
Read Full Article