Recent years have seen the tables turn on internet giants such as Facebook, Google, and Twitter. Censorship is a word on the lips of people around the globe.
Are the de facto controllers of internet information and dissemination doing enough—or too little—to protect users from negative content while protecting the core tenets of free speech?
A leaked internal research presentation suggests that Google is struggling to find a balance, an existential crisis of sorts. Can tech giants actively protect against the negative aspects of free speech without censoring and destroying the voices of others?
Google: The Good Censor

The internal research presentation was leaked to Breitbart News and is titled “The Good Censor.” The Good Censor offers a rare and almost unprecedented look into how Google struggles to mediate its position at the center of the internet.
Google is a powerful institute in the ebb and flow of internet censorship. The leaked presentation explores the idea that 21st century tech companies “are performing a balancing act between two incompatible positions.”
They’re not wrong.
Who Controls the Internet?
“Is it possible to have an open and inclusive internet while simultaneously limiting political oppression and despotism, hate, violence, and harassment? Who should be responsible for censoring ‘unwanted’ conversation, anyway?”
It is no secret that the online platforms we use are facing unparalleled pressure to moderate the conversation. It isn’t just online, either. The actions and activities taking place across social networks such as Facebook have a direct effect in the “offline” world (as if there is really any boundary between the two, anyway).
The presentation has a few interesting tidbits as to where Google believes the internet is heading, as well as Google’s position.
Perhaps most interesting is that the document appears to contradict Google’s long-held position that it isn’t a media company. Google uses this line of defense to protect from liabilities.
But the distinction that helped Google, Facebook, Twitter, and other social media platforms grow has become increasingly blurry in recent years.
Free speech is “instilled in the DNA of the Silicon Valley startups that now control the majority of our online conversations.” The presentation also acknowledges the role of Section 230 of the Communications Decency Act of 1996 on social media’s explosive growth. The statute effectively grants technology companies immunity from the content posted on the platform.
This distinction is different from traditional media and has empowered Facebook, Twitter, Reddit, and YouTube to become bastions of free speech without fear of consequence (for the companies, not the users).
A Vacuum of Free Speech
As a focal point for public opinion, and so often the loudspeaker of the masses, Google, Facebook, Reddit, and Twitter have had an unmatched role in major recent events.
“The internet was founded on Utopian principles of free speech…”
And the internet has undoubtedly allowed free speech to flourish. The Arab Spring almost certainly would not have taken place without the protected environments of social media. (Here are some tech-savvy ways people work around censorship.)
But within the vacuum of social media, and as Google’s research document declares, “recent global events have undermined this Utopian narrative.” The idea of a Utopian and genuinely egalitarian internet was dead long ago. The Google research document isolates specific incidents in recent years that illustrate how unbridled free speech can damage.
The End of Internet Utopia?
Specifically:
- The Ferguson Unrest
- Leslie Jones vs. Trolls
- US Election 2016
- Kashmir Clashes in India
- The Philando Castile shooting aftermath
- The Rise of the Alt-Right
- Queermuseu in Brazil
- YouTuber Logan Paul
The events chosen to illustrate the Google research explore the wider role of tech companies in censorship, intentional or not. For instance, the Ferguson protests exposed the difference between platform algorithms. During Ferguson, Twitter was full of detailed accounts of the event, with Facebook was full of the Ice Bucket Challenge. Algorithms can effectively censor the news depending on the platform.
During the 2016 US Presidential Election, over 80,000 Russian-based posts allegedly influenced up to 126 million Facebook users. The posts steered conversations, revealing the “scope and potential impact of fake news on democracy.”
Actress Leslie Jones was subject to a prolonged and persistent sexist and racist Twitter troll campaign. She eventually quit the platform. In the aftermath, a number of alt-right Twitter accounts received platform bans, including the prominent Milo Yiannopolous. Twitter alleged that Yiannopolous was the ringleader of the campaign.
Yiannopolous claimed “This is the end for Twitter. Anyone who cares about free speech has been sent a clear message: ‘You’re not welcome on Twitter.'” (Fortunately, there are Twitter alternatives for you to try.)
Over at YouTube, a series of major brands boycotted the platform after their ads were shown alongside recruiting material for extremist organizations, including ISIS. Google promised to reform their advertising policies (as they did in response to the Logan Paul issue, too).
However, reforms stopped short of ridding YouTube from such material in its entirety because doing so would “place them entirely in the realm of ‘curator and censor.'”
Tech Companies Censor for Governments
For a long time, tech companies played a single, extremely handy get-out-of-jail-free card: “we’re not responsible for what happens on our platforms.” Google, Facebook, Twitter, and others have trotted the defense out so many times that it is now the expectation, with very little questioning. However, Google, and I’m sure the other platforms, are aware that the times are changing. If the tech companies don’t want governments to interfere, then there must be self-regulation, right?
The truth is that we cannot expect governments to act in good faith, either. There are too many instances of governments using tech companies to do their bidding. Plus, the speed of development at tech companies makes it hard for governments to keep up.
In that case, governments have two choices: develop laws with vast overreach, or apply old laws to new tech. It also creates a negative “with us or against us” mentality, where you’re either helping the government, or you are a threat.
As you have seen above, mixed-use social media sites are a (sort of) positive in the fight for censorship. If a government wants to have a piece of content removed, they have to make a formal request.
The yearly Electronic Frontier Foundation “Who Has Your Back” study shows how sites handle requests (see the full “Who Has Your Back” PDF comparison.) Most notably, YouTube receives a full five stars, showing that meaningful censorship can take place. However, this is without examining the details of the reams of content removed from the platform.
Lawful Content Takedown
Tech companies don’t always roll over and agree to a request. There are numerous examples of Apple refusing to cooperate with the government (albeit, the issue usually relates to encryption rather than censorship). In January 2017, US Customs and Border Protection requested Twitter provide the identity of a user who objected to President Trump’s immigration policy.
Twitter took them to court, and Customs and Borders backed down.
Tech companies will comply. Of course, they will; it is the law. But in that, the tech companies only comply with lawful data collection and removal requests. And the numbers of requests have drastically increased in recent years, at least according to transparency reports released by Google, Facebook, Twitter, and Reddit. The below image comes from Google’s “Removal requests by the numbers” section.
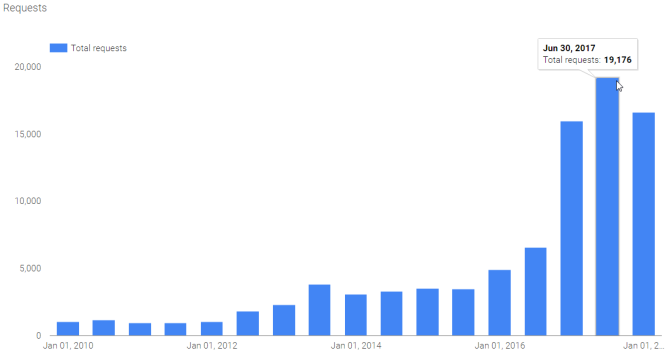
The rising numbers show that governments around the world are “also trying to tighten their grip on political discourse” by asking tech companies to censor damaging content.
Are Tech Companies Failing the Public on Censorship?
The Google research report is very honest. There are failings. Tech firms:
- Incubate fake news by allowing “dubious distributors” to take advantage of the lack of platform checks, gaming algorithms that automatically display news items.
- Have “ineffective automation” that cannot cope with the demands of moderation. With so much content, moderation is turned over to AI, meaning a large number of appropriate videos also fall foul of censorship. Overturning wrongful AI censorship decisions can also take a long time.
- Commercialize the online conversation by making sure the most advertising revenue friendly content “wins” social media.
- Are unfathomably inconsistent regarding the censorship of certain groups and activities.
- Regularly underplay the issues of negative or scandal concerning their platforms until hard fact proves otherwise. At that point, the tact switches and it becomes a PR-cover up game of damage limitation, with the real issue never resolved.
- Are slow to correct false censorship (see also point two, above).
- Often use reactionary tactics in the hope issues blow over before forcing action. In the meantime, platform users and government agencies can speculate, while anger relating to the issue explodes.
So, are tech companies failing the public with regards to censorship?
Yes.
But the tech companies are trying to make amends. Governments are, too, despite their use of social media and tech companies as tools of censorship. In an age where everyone wants to share their opinion, where platforms want users to feel safe, and where that safety can maximize advertising profit (which is, of course, the be all and end all of the internet), censorship will only continue to expand.
As censorship demand fluctuates depending on political mood or major global controversy, only one thing is certain: Google and other tech companies have little chance of pleasing everyone.
Read the full article: The Google Censorship Leak: Are You Being Censored?
Read Full Article