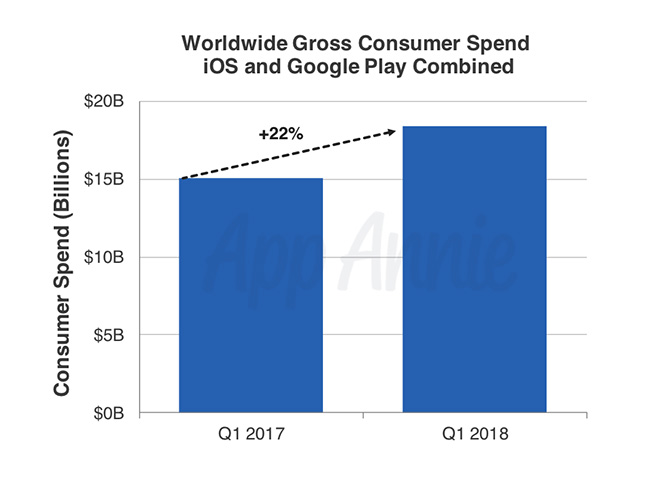
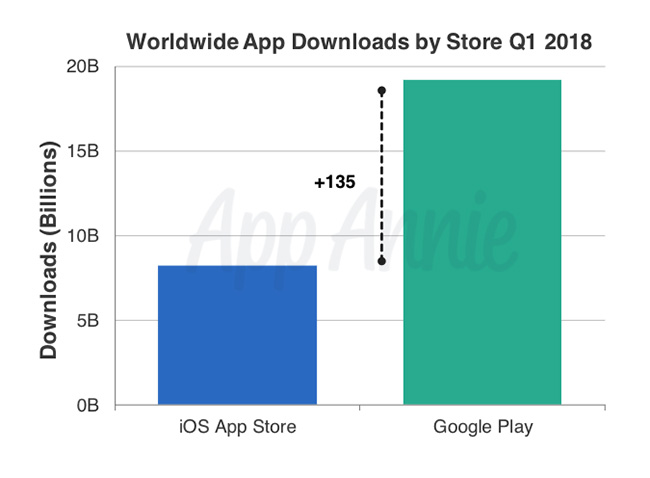
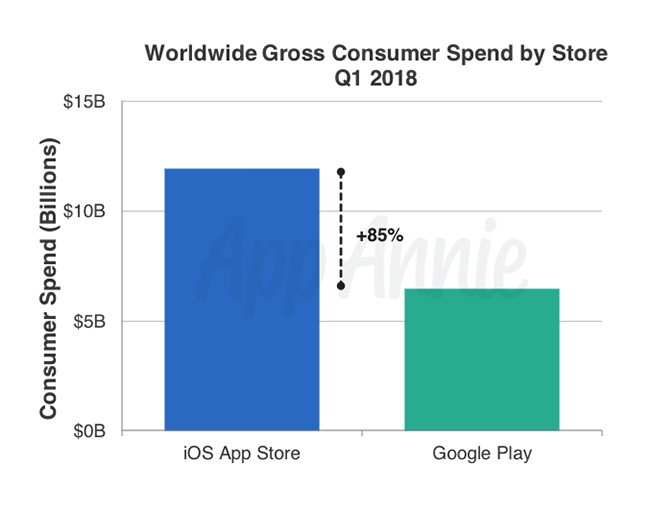
It’s official: Bots are doing a lot of PR grunt work on Twitter — especially when it comes to promoting porn websites.
That perhaps unsurprising conclusion about what automated Twitter accounts are link sharing comes courtesy of a new study by the Pew Research Center which set out to quantify one aspect of bot-based activity in the Twittersphere.
Specifically the researchers wanted to know what proportion of tweeted links to popular websites are posted by automated accounts, rather than by human users?
The answer they came up with is that around two-thirds of tweeted links to popular websites are posted by bots rather than humans.
The researchers say they were interested in trying to understand a bit more about how information spreads on Twitter. Though for this study they didn’t try to delve directly into more tricky (and sticky) questions about bots — like whether the information being spread by these robots is actually disinformation.
Pew’s researchers also didn’t try to determine whether the automated link PR activity actually led to significant levels of human engagement with the content in question. (Something that can be difficult for external researchers to determine because Twitter does not provide full access to how it shapes the visibility of tweets on its platform, nor data on how individual users are making use of controls and settings that can influence what they see or don’t on its platform).
So, safe to say, many bot-related questions remain to be robustly investigated.
But here at least is another tidbit of intel about what automated accounts are up to vis-a-vis major media websites — although, as always, these results are qualified as ‘suspected bots’ as a consequence of how difficult it is to definitively identify whether an online entity is human or not. (Pew used Indiana University’s Botometer machine learning tool for identifying suspected bots; relying on a score of 0.43 or higher to declare likely automation — based on a series of their own validation exercises.)
Pew’s top-line conclusion is that suspected automated accounts played a prominent role in tweeting out links to content across the Twitter ecosystem — with an estimated 66% of all tweeted links to the most popular websites likely posted by automated accounts, rather than human users.
The researchers determined website popularity by first conducting an analysis of 1.2 million English-language tweets containing links (pulling random sample tweet data via Twitter’s streaming API) — which they boiled down to a list of 2,315 popular sites, i.e. once duplicates and dead links were weeded out.
They then categorized these into content domains, with any links that pointed to any other content on Twitter (i.e. rather than externally) collected into a single Twitter.com category.
After that they were able to compare how (suspected) bots vs (probable) humans were sharing different categories of content.
Below are the results for content being PRed by suspected bots — as noted above it’s unsurprisingly dominated by adult content. Though bots were found to be responsive for the majority of link shares to popular websites across the category board. Ergo, robots are already doing a major amount of PR grunt work…
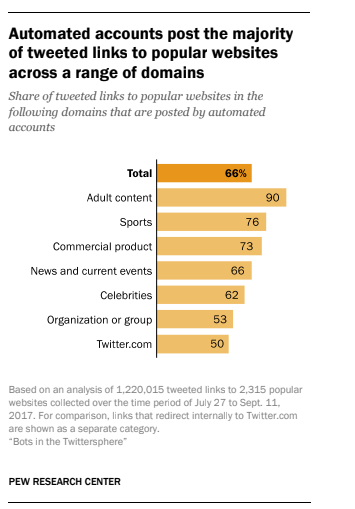
(Looking at that, a good general rule of thumb seems to be that if a Twitter account is sharing links to porn sites it’s probably not human. Or, well, it’s a human’s account that’s been hacked.)
The researchers also found that a relatively small number of automated accounts were responsible for a substantial share of the links to popular media outlets on Twitter. “The 500 most-active suspected bot accounts alone were responsible for 22% of all the links to these news and current events sites over the period in which this study was conducted. By contrast, the 500 most-active human accounts were responsible for just 6% of all links to such sites,” they write.
Clearly bots aren’t held back by human PR weaknesses — like needing to stop working to eat or sleep.
Pew says its analysis also suggests that certain types of news and current events sites appear “especially likely” to be tweeted by automated accounts. “Among the most prominent of these are aggregation sites, or sites that primarily compile content from other places around the web. An estimated 89% of links to these aggregation sites over the study period were posted by bot accounts,” they write.
tl;dr: Bots appear to be less interested in promo-ing original reporting. Or, to put it another way, bot grunt work is often being deployed to try to milk cheap views out of other people’s content.
Another interesting observation: “Automated accounts also provide a somewhat higher-than-average proportion of links to sites lacking a public contact page or email address for contacting the editor or other staff.
“The vast majority (90%) of the popular news and current events sites examined in this study had a public-facing, non-Twitter contact page. The small minority of sites lacking this type of contact page were shared by suspected bots at greater rates than those with contact pages. Some 75% of links to such sites were shared by suspected bot accounts during the period under study, compared with 60% for sites with a contact page.”
Without reading too much into that finding, it’s possible to theorize that sites without any public content page or email might be more likely to be hosting disinformation. (Pew’s researchers don’t go as far as to join those dots exactly — but they do note: “This type of contact information can be used to submit reader feedback that may serve as the basis of corrections or additional reporting.”)
That said, Pew also found political content to be of relatively lower interest to bots vs other types of news and current affairs content — at least judging by this snapshot of English-language tweets (taken last summer).
“[C]ertain types of news and current events sites receive a lower-than-average share of their Twitter links from automated accounts,” the researchers write. “Most notably, this analysis indicates that popular news and current events sites featuring political content have the lowest level of link traffic from bot accounts among the types of news and current events content the Center analyzed, holding other factors constant. Of all links to popular media sources prominently featuring politics or political content over the time period of the study, 57% are estimated to have originated from bot accounts.”
The researchers also looked at political affiliation — to try to determine whether suspected bots skew left or right in terms of the content they’re sharing.
(To determine the ideological leaning of the content being linked to on Twitter Pew says they used a statistical technique known as correspondence analysis — examining the media link sharing behavior of publications’ Twitter audience in order to score the content itself on an idealogical spectrum ranging from “very liberal” to “most conservative”.)
In fact they found automated accounts posting a greater share of content from sites that have “ideologically mixed or centrist human audiences”. At least where popular news and current events sites “with an orientation toward political news and issues” are concerned.
“The Center’s analysis finds that suspected autonomous accounts post a higher proportion of links to sites that are primarily shared by human users who score near the center of the ideological spectrum, rather than those shared more often by either a more liberal or a more conservative audience,” they write. “Automated accounts share roughly 57% to 66% of the links to political sites that are shared by an ideologically mixed or centrist human audience, according to the analysis.”
Pew adds that right-left differences in the proportion of bot traffic were “not substantial”.
Although, on this, it’s worth emphasizing that this portion of the analysis is based on a pretty small sub-set of an already exclusively English-language and US-focused snapshot of the Twittersphere. So reading too much into this portion of the analysis seems unwise.
Pew notes: “This analysis is based on a subgroup of popular news and current events outlets that feature political stories in their headlines or have a politics section, and that serve a primarily U.S. audience. A total of 358 websites out of our full sample of 2,315 popular sites met these criteria.”
Really the study underlines a core truth about Twitter bots: They’re often used for spam/PR purposes — to try to drive traffic to other websites. The substance of what they’re promoting varies, though it can clearly often be adult content.
Bots are also often used to try to cheaply drive clicks to a cheap content aggregator site so that external entities can cheaply cash in thanks to boosted ad views and revenue.
Political disinformation campaigns may well result in a lower volume of bot-generated spam/PR than porn or content farms. Though the potential damage — to democratic processes and societal institutions — is arguably way more serious. As well as being very difficult to quantify.
And where the influence of bots is concerned, we still have many more questions than answers.
 Read Full Article
Read Full Article
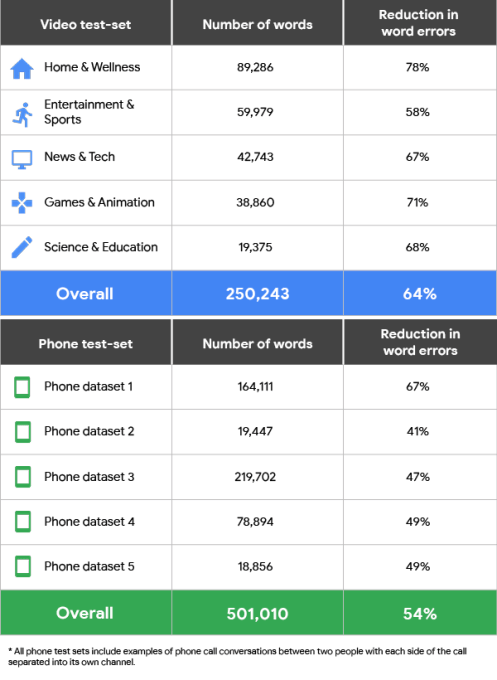 Part of this improvement is a major new feature in the Speech-to-Text API that now allows developers to select between different machine learning models based on this use case. The new API currently offers four of these models. There is one for short queries and voice commands, for example, as well as one for understanding audio from phone calls and another one for handling audio from videos. The fourth model is the new default, which Google recommends for all other scenarios.
Part of this improvement is a major new feature in the Speech-to-Text API that now allows developers to select between different machine learning models based on this use case. The new API currently offers four of these models. There is one for short queries and voice commands, for example, as well as one for understanding audio from phone calls and another one for handling audio from videos. The fourth model is the new default, which Google recommends for all other scenarios.