
Data Error

After months of statements, the biggest challenge yet to T-Mobile and Sprint’s proposed merger kicks off today in a Manhattan court. The trial is the result of pushback from a coalition of attorneys general of 13 states and the District of Columbia, who have raised flags over the proposed $26 billion merging of the country’s third- and fourth-largest carriers.
“Today we stand on the side of meaningful competition and affordable options for consumers,” California Attorney General Xavier Becerra said in a statement provided to TechCrunch. “Our airwaves belong to the public, who are entitled to more, not less. This merger would hurt the most vulnerable people among us– leaving consumers with fewer choices and higher prices. We’re fighting in court with a 14-state strong coalition for then, and for all Americans, and we’re confident the law is on our side.”
The AGs contend that such a merger will decrease competition in the U.S. telecom market, by knocking the number of major carriers down to three. T-Mobile and Sprint, on the other hand, have argued that it will do the opposite, suggesting that the companies’ pooled powers would better equip them to take on Verizon and AT&T in the rush to 5G.
Over the summer, FCC Chairman Ajit Pai issued an order essentially arguing with the carriers and suggested the deal move forward. “The evidence conclusively demonstrates that this transaction will bring fast 5G wireless service to many more Americans and help close the digital divide in rural areas,” he said in August.
The trial is expected to last three weeks, per The Wall Street Journal, kicking off with today’s opening statements. Sprint Chairman Marcelo Claure and soon-to-be-former T-Mobile CEO John Legere will take the stand to make their case against the AGs.



Mindstrong Health is tackling one one of the most difficult challenges in healthcare: Severe mental illness, commonly referred to as SMI in the healthcare industry. The startup, founded in 2013 by Paul Dagum, Richard Klausner and Thomas Insel, recently brought on former Uber VP of Product Daniel Graf as CEO, and is now announcing a number of new hires to its senior product leadership team as it moves to turn the technology and research it’s developed over the past six years into an even more compelling and user-friendly product.
As mentioned, Graf was Mindstrong Health‘s first high-profile hire this year, when the former Uber, Twitter and Google product leader joined in October. Graf’s turn as the company’s chief executive is his return to the operational side after spending some time away from building product as an investor. He and Mindstrong have brought in four new c-suite execs to lead the company, including a new CPO, COO and CTO, as well as a new VP of Data Science and new VP of Marketing.
The CPO role is the only one Mindstrong can’t yet disclose, bu the incoming person has been a product leader at large tech companies, Graf told me in an interview. Meanwhile, the company is revealing that Brandon Trew (ex Uber, Google) will join as COO, Erik Albair (ex Google Maps, DeepMind) will join as CTO, Kane Sweeney (ex Uber, StubHub) comes in as VP of Data Science and Dena Olyaie (ex Facebook, Oscar Health) joins as VP of Marketing.
“The inflection point we’re going through now is really building out the whole foundation,” Graf told me. “If you look at our [current] app, it’s not an app, I would us as a consumer and from an experience point of view – it’s a science app. We basically have to build this whole foundation and platform, so for a technology person for a product person for a data scientist, for a marketing person, it’s kind of a dream. When you look at the planning stage, you look at the mission, with amazing investors, we don’t really have to worry about investments, and we can build this now. We can build this amazing platform and that’s why all these folks are joining.”
Mindstrong Health’s primary product is a platform that provides remote care on-demand for patients dealing with SMI. This group in particular faces challenges with current health care options, because they often face long wait times for appointments with qualified medical professionals, but their issues are pressing, hard to predict and often immediate in nature. Traditional care is also very expensive, and Mindstrong’s model has been shown to drive better results for patients, and to lower cost for insurance companies and other payers. Backed by ARCH Venture Partners, General Catalyst, Bezos Expeditions and more, the company has a number of ongoing trials with healthcare providers and patients, and based on the positive outcomes they’ve seen from this work the goal now is to refine and prepare the product for commercial use.
Graf’s new leadership team also shares a lot of experience building products that benefit from optimization based on interpretation of large data sets, and that’s also not a coincidence. Part of Mindstrong’s unique approach has been developing a way to quantify SMI issues in a way that makes it possible to anticipate problems based on signals from how a user is interacting with the app, including typing speed an other cues, as compared to an established personal baseline. It’s a big data problem, but instead of solving something like routing on-demand transportation, it’s tackling the issue of delivering reliable, quality care to individuals who are most in need.
Google this morning announced the arrival of its first “feature drop.” The new offering will continue the company’s regular feature enhancements, now arriving every month, like clockwork. This first one brings a whole bunch of upgrades, including a few already noted by some eagle eye views.
The call screen update is probably the biggest of the bunch. This one drops for Pixel 4 users in the U.S. to start, giving users screen unknown callers, filtering our robocalls in the process. When it’s not spam, users will get a notification shortly after featuring a transcript of the message. Google notes that all of that info is kept private to the the user, per the below gif.
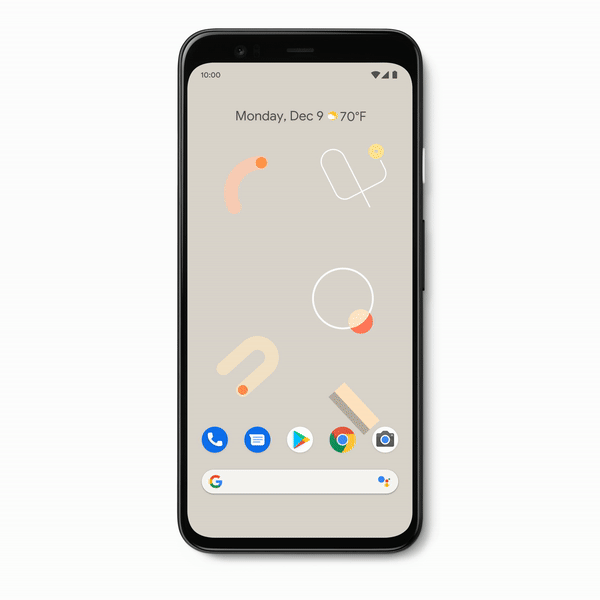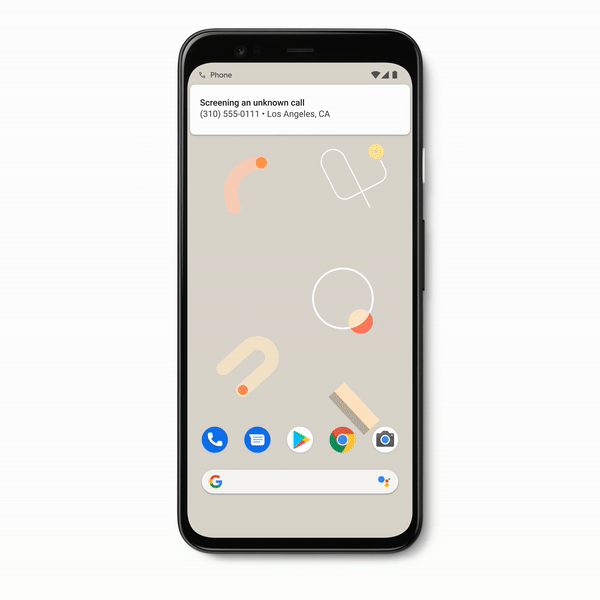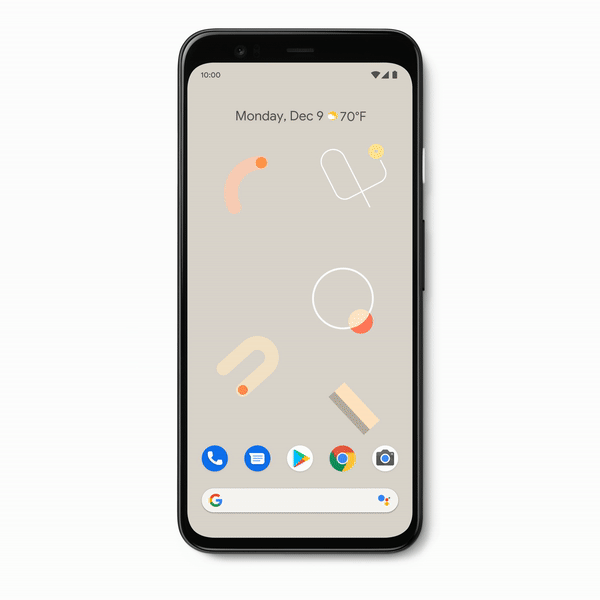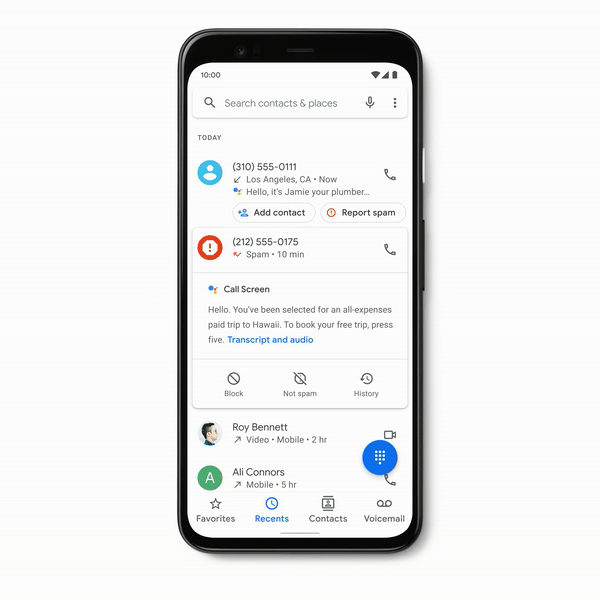
The Photos app gets a handy update, making it possible to add a background faux-bokeh blur to portrait photos, for the those times you forget to turn the feature on while shooting.
The Pixel 4 gets some key Duo improvements, as well, including auto framing, which keeps one or two people centered The feature appears to look similar to the more sophisticated versions found on the Nest Home Max (and Facebook’s Portal before it), zooming in and out to get people in frame.
Duo calls on the Pixel 2-4 also get a bokeh effect to blur out the background during calls, along with Smooth Display, which should offer better playback on spotty connections.
Also of note is the recently announced arrival of the extremely handy Recorder app on older Pixel models, along with the addition of Live Caption for the Pixel 3 and 3a. Users in UK, Canada, Ireland, Singapore and Australia, meanwhile, will be getting the updated version of Google Assistant soon, as well.

