Google just released an advert for Google Assistant and its band of merry products. It’s really good. Basically the ad is Home Alone reimagine, but this time Macaulay Culkin plays an adult Kevin who home alone with a house full of devices controlled by Google Assistant. Obviously.
And for the sake of objectivity, I need to point out a home outfitted with Amazon or Apple’s voice assistants could do the same thing.
A coalition of twenty-two consumer and public health advocacy groups, led by Campaign for a Commercial-Free Childhood (CCFC) and Center for Digital Democracy (CDD), have today filed a complaint with the Federal Trade Commission asking them to investigate and sanction Google for how its Google Play Store markets apps to children. The complaint states that Google features apps designed for very young children in its Play Store’s “Family” section, many of which are violating federal children’s privacy law, exposing kids to inappropriate content, and disregarding Google’s own policies by luring kids into making in-app purchases and watching ads.
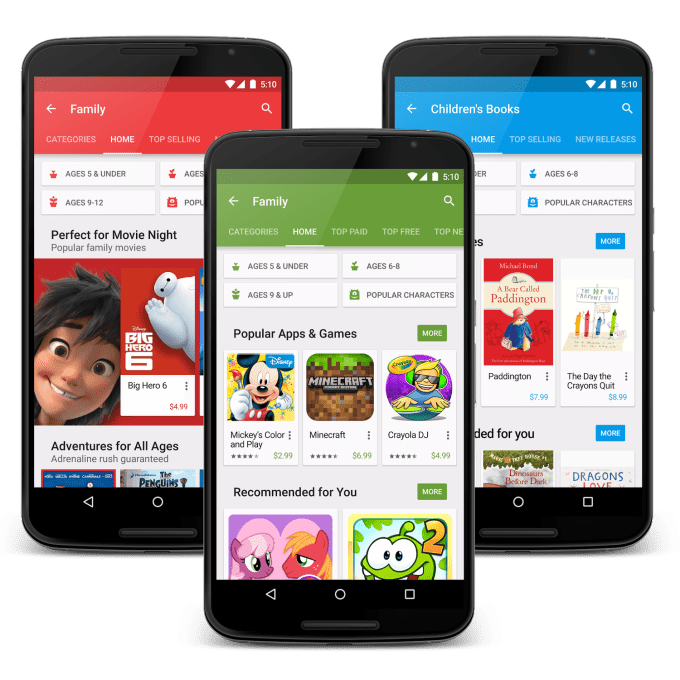
Google Play ‘Family’ Section
Google first introduced its “Designed for Families” program back in 2015, which gives developers of kid-friendly apps meeting certain guidelines additional visibility in the Play Store. This includes a placement in the Family section, where apps are organized by age appropriateness.
COPPA is designed to protect children under the age of 13 by giving parents control over what information sites and apps can collect from their kids.
Above: Google Play store showcases children’s content in its own dedicated sections
COPPA Violations
But the new FTC complaint claims that Google is not verifying COPPA compliance when it accepts these apps and, as a result, many are in continual violation of the law.
“Our research revealed a surprising number of privacy violations on Android apps for children, including sharing geolocation with third parties,” said Serge Egelman, a researcher at the University of California, Berkeley, in a statement shared by the group. “Given Google’s assertion that Designed for Families apps must be COPPA compliant, it’s disappointing these violations still abound, even after Google was alerted to the scale of the problem,” he added.
TechCrunch asked the coalition if it had some idea about how many apps were in violation of COPPA, and were told the groups don’t know an exact number.
“From our survey – and more comprehensive analyses like the PET Study – it seems fairly prevalent,” Lindsey Barrett, Staff Attorney at Georgetown’s Institute for Public Representation, told us.
“The PET Study found that 73% of the kids apps in the Play store transmitted sensitive data over the internet, and we saw apps sending geolocation without notice and verifiable parental consent, and sending personal information unencrypted,” Barrett said. “Further, under COPPA, children’s PII cannot be used for behavioral advertising. Yet, many of the children’s apps we looked at were sending information to ad networks which say their services should not be used with children’s apps,” she added.
Other Harms
The apps also engage in other bad behaviors like regularly showing ads that are difficult to exit or showing those that require viewing in order to continue the current game, according to the complaint. Some apps pressure kids into making in-app purchases – in one example, the game characters were crying if the kids didn’t buy the locked items, it notes. Others show ads for alcohol and gambling, despite those being barred by Google’s Ad Policy.
Above: disturbing images from TabTale apps
The coalition additionally called out some apps for containing “graphic, sexualized images” like TutoTOONS Sweet Baby Girl Daycare 4 – Babysitting Fun, which has over 10 million downloads. (The game has a part where kids change a baby’s diaper, wipe their diaper area, then rub powder all over the baby’s body.) Others model harmful behavior, like TabTale’s Crazy Eye Clinic, which teaches children to clean their eyes with a sharp instrument, and has over one million downloads. (The game is currently not available on Google Play and its webpage is down.)
The complaint also broadly takes issue with apps that use common SDKs like those from Unity or Flurry (disclosure: Flurry and TechCrunch share a corporate parent) to collect device identifiers from the children’s apps.
“Nearly three-quarters of the apps in the Family section transmit device identifiers to third parties,” reads the complaint. “There is no way for us to know for sure what the device identifiers are used for. Since many of the apps send device identifiers to third parties that specialize in monetizing apps and/or engaging in interest-based (behavioral) advertising, it seems unlikely that this information is being used solely to support internal operations,” it says.
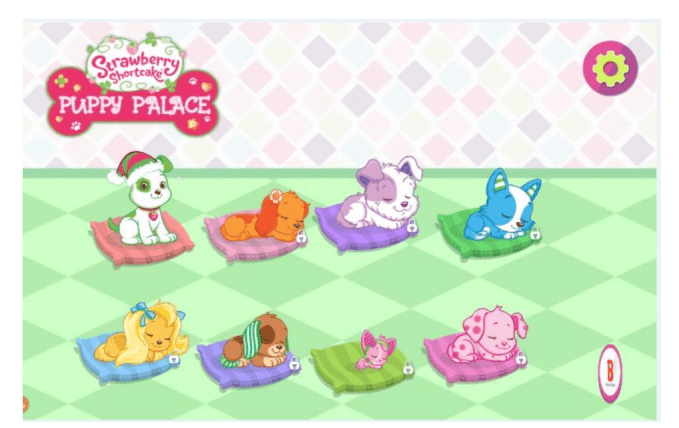
Above: Strawberry Shortcake Puppy Palace was called out for aggressive monetization efforts. Strawberry tells kids to buy things to keep the puppy happy – the implication is if you don’t pay, you’re making puppies sad.
The groups say that Google has been aware of all these problems for some time, but hasn’t taken adequate steps to enforce its criteria for developers. As a result, the consumer advocacy groups are urging the FTC to investigate the Play Store’s practices.
The coalition had previously asked the FTC to investigate developers of children’s apps aimed a preschoolers who were using manipulative advertising. But today’s complaint is focused on Google.
“Google (Alphabet, Inc.) has long engaged in unethical and harmful business practices, especially when it comes to children,” explained Jeff Chester, executive director of the Center for Digital Democracy. “And the Federal Trade Commission has for too long ignored this problem, placing both children and their parents at risk over their loss of privacy, and exposing them to a powerful and manipulative marketing apparatus. As one of the world’s leading providers of content for kids online, Google continues to put the enormous profits they make from kids ahead of any concern for their welfare,” Chester said.
Apple was not similarly called out because a similar analysis has not yet been done on its app marketplace, Josh Golin, Executive Director at CCFC told us. In Google’s case, he explained, two major studies found widespread issues with the Play Store apps for kids. One from Berkeley researchers found widespread COPPA non-compliance; the other, by University of Michigan researchers, found children’s play experience was often completely interrupted and undermine by aggressive marketing tactics.
The complaint comes at a time where there is increased scrutiny as to how tech companies are misusing and abusing consumer data and violating privacy. Kids game have already been the subject of some of some concern. And this morning, an NYT investigation into Facebook revealed it had shared more of users’ personal data than disclosed with major tech companies, following a year of data scandals.
The issue of data privacy is an industry-wide problem. Tech companies’ failures on this front will likely lead to increased regulation going forward.
Google and the named developers were not immediately available to comment this morning. We’ll update if comments are provided.
A coalition of twenty-two consumer and public health advocacy groups, led by Campaign for a Commercial-Free Childhood (CCFC) and Center for Digital Democracy (CDD), have today filed a complaint with the Federal Trade Commission asking them to investigate and sanction Google for how its Google Play Store markets apps to children. The complaint states that Google features apps designed for very young children in its Play Store’s “Family” section, many of which are violating federal children’s privacy law, exposing kids to inappropriate content, and disregarding Google’s own policies by luring kids into making in-app purchases and watching ads.
Google first introduced its “Designed for Families” program back in 2015, which gives developers of kid-friendly apps meeting certain guidelines additional visibility in the Play Store. This includes a placement in the Family section, where apps are organized by age appropriateness.
COPPA is designed to protect children under the age of 13 by giving parents control over what information sites and apps can collect from their kids.
Above: Google Play store showcases children’s content in its own dedicated sections
But the new FTC complaint claims that Google is not verifying COPPA compliance when it accepts these apps and, as a result, many are in continual violation of the law.
“Our research revealed a surprising number of privacy violations on Android apps for children, including sharing geolocation with third parties,” said Serge Egelman, a researcher at the University of California, Berkeley, in a statement shared by the group. “Given Google’s assertion that Designed for Families apps must be COPPA compliant, it’s disappointing these violations still abound, even after Google was alerted to the scale of the problem,” he added.
TechCrunch asked the coalition if it had some idea about how many apps were in violation of COPPA, and were told the groups don’t know an exact number.
“From our survey – and more comprehensive analyses like the PET Study – it seems fairly prevalent,” Lindsey Barrett, Staff Attorney at Georgetown’s Institute for Public Representation, told us.
“The PET Study found that 73% of the kids apps in the Play store transmitted sensitive data over the internet, and we saw apps sending geolocation without notice and verifiable parental consent, and sending personal information unencrypted,” Barrett said. “Further, under COPPA, children’s PII cannot be used for behavioral advertising. Yet, many of the children’s apps we looked at were sending information to ad networks which say their services should not be used with children’s apps,” she added.
The apps also engage in other bad behaviors like regularly showing ads that are difficult to exit or showing those that require viewing in order to continue the current game, according to the complaint. Some apps pressure kids into making in-app purchases – in one example, the game characters were crying if the kids didn’t buy the locked items, it notes. Others show ads for alcohol and gambling, despite those being barred by Google’s Ad Policy.
Above: disturbing images from TabTale apps
The coalition additionally called out some apps for containing “graphic, sexualized images” like TutoTOONS Sweet Baby Girl Daycare 4 – Babysitting Fun, which has over 10 million downloads. (The game has a part where kids change a baby’s diaper, wipe their diaper area, then rub powder all over the baby’s body.) Others model actively harmful behavior, like TabTale’s Crazy Eye Clinic, which teaches children to clean their eyes with a sharp instrument, and has over one million downloads. (The game is currently not available on Google Play and its webpage is down.)
The complaint also broadly takes issue with apps that use common SDKs like those from Unity or Flurry (disclosure: Flurry and TechCrunch share a corporate parent) to collect device identifiers from the children’s apps.
“Nearly three-quarters of the apps in the Family section transmit device identifiers to third parties,” reads the complaint. “There is no way for us to know for sure what the device identifiers are used for. Since many of the apps send device identifiers to third parties that specialize in monetizing apps and/or engaging in interest-based (behavioral) advertising, it seems unlikely that this information is being used solely to support internal operations,” it says.
The groups say that Google has been aware of all these problems for some time, but hasn’t taken adequate steps to enforce its criteria for developers. As a result, the consumer advocacy groups are urging the FTC to investigate the Play Store’s practices.
The coalition had previously asked the FTC to investigate developers of children’s apps aimed a preschoolers who were using manipulative advertising. But today’s complaint is focused on Google.
“Google (Alphabet, Inc.) has long engaged in unethical and harmful business practices, especially when it comes to children,” explained Jeff Chester, executive director of the Center for Digital Democracy. “And the Federal Trade Commission has for too long ignored this problem, placing both children and their parents at risk over their loss of privacy, and exposing them to a powerful and manipulative marketing apparatus. As one of the world’s leading providers of content for kids online, Google continues to put the enormous profits they make from kids ahead of any concern for their welfare,” Chester said. “It’s time federal and state regulators acted to control Google’s ‘wild west’ Play Store App activities,” he added.
Apple was not similarly called out because a similar analysis has not yet been done on its app marketplace, Josh Golin, Executive Director at CCFC told us. In Google’s case, he explained, two major studies found widespread issues with the Play Store apps for kids. One from Berkeley researchers found widespread COPPA non-compliance; the other, by University of Michigan researchers, found children’s play experience was often completely interrupted and undermine by aggressive marketing tactics.
The complaint comes at a time where there is increased scrutiny as to how tech companies are misusing and abusing consumer data and violating privacy. Kids game have already been the subject of some of some concern. And this morning, an NYT investigation into Facebook revealed it had shared more of users’ personal data than disclosed with major tech companies, following a year of data scandals.
The issue of data privacy is an industry-wide problem. Tech companies’ failures on this front will likely lead to increased regulation going forward.
Google and the named developers were not immediately available to comment this morning. We’ll update if comments are provided.
Sprout Social, a social media monitoring, marketing and analytics service with 25,000 business customers that helps these organizations manage their public profiles and interact with customers across Twitter, Facebook, Instagram, LinkedIn, Pinterest and Google+ (soon to RIP), has raised $40.5 million in funding in order expand its business internationally and add more functionality to its platform.
The money — a Series B led by Future Fund with participation from Goldman Sachs and New Enterprise Associates — brings the total raised by Sprout to $103.5 million to date. We’ve asked the company about its valuation, and we’ll update as we learn more. For some context, Sprout last raised in 2016 — $42 million also from Goldman Sachs and NEA — and at the time it had a post-money valuation of $253 million, according to PitchBook.
That cold mean that the valuation now is just shy of $300 million. But between then and now, there have been some interesting developments that could have shifted that price in either direction.
On one side, multiple sources have told us that Sprout was being courted by Microsoft for acquisition at one point (both companies declined to comment on this for us at the time we were looking into it). One reason, one source told us, that the deal didn’t go through was because they couldn’t reach a deal on pricing.
On the other, one of Sprout’s biggest competitors, Hootsuite (with 15 million users, paid and free), has been rumored to be shopping itself for about $750 million, or potentially going public, while smaller competitors have moved in on some consolidation to bulk up their own presence in the field.
In the meantime, Sprout itself has been growing. The company’s 25,000 customers are up from 16,000 two years ago, with current users including Microsoft, NBCUniversal, the Denver Nuggets and Grubhub and MTV.
One of the reasons for the growth is the larger shift we’ve seen in how businesses interact with the outside world. Social media is today perhaps the most important platform for businesses to communicate with their users: not only has social media helped customers circumvent the often frustrating spaghetti that lies behind the deceptive phrase “contact us” on websites, but social media has become a spotlight, which businesses have to watch lest a sticky situation snowballs into a public relations disaster.
Platforms like Twitter and Facebook, to grow their revenues, have ramped up their efforts to work on social media campaigns and interactions directly with organizations. But there is still a place for third parties like Sprout Social to manage work that goes across a number of social sites, and to address services that the social platforms themselves do not necessarily want to invest in building directly.
“I think there are a bunch of reasons why we don’t build bot experience ourselves,” Jeff Lesser, who heads up product marketing for Twitter Business Messaging, told me when Sprout launched a “bot builder” to be used on Twitter, and I asked him why Sprout shouldn’t worry about Twitter cannibalizing its product. “There are millions of types of businesses that can use our platform, so we’re letting the ecosystem build the solutions that they need. We are focusing on building the canvas for them to do that.”
In other words, while Sprout (and competitors) should always be a little wary of platform players who may decide to simply kick them off in the name of business, there are always going to be opportunities if they have the resources double down on more tech to solve a different problem, or simply execute on fixing an existing problem better.
“Social marketing and social data have become mission-critical to virtually all aspects of business. Sprout’s relentless focus on quality and customer success have made us the top customer-rated platform in every category and segment,” said Justyn Howard, CEO of Sprout, in a statement. “In many ways, social is still in its infancy, and we’re fortunate to help so many great customers navigate this evolving set of challenges.”
Want to know what the best cheap VPN deal is for you right now? Some of the top VPN services are cutting prices temporarily and giving new customers some great deals, and we’ve rounded up some of the best available right now.
First, let’s look at an awesome Christmas VPN deal from CyberGhost, who are offering an MakeUseOf readers discounts on all subscription plans from December 20th until December 25th.
Our review of CyberGhost revealed a service that enables anonymous surfing of the web, handles video streaming well, and even supports safe torrent downloads.
Observing it as a “top VPN for beginners” thanks to it’s simple setup and easy apps on every platform, we concluded that CyberGhost’s “confident no-logging policy is a definite advantage, while the VPN’s speed is up there with the best. CyberGhost is a secure, fast VPN.”
VPN Unlimited is dropping prices this week, with savings on its 12 month and 36 month deals.
With support for five devices, you can get VPN access from $5 a month if you pay $59.99 up front (which includes three months free). Alternatively, pay for three years at just $99.99 to gain a 75% discount, which works out at a very affordable $2.78 per month.
With 7-day money back option and 24/7 support, VPN Unlimited has access to over 400 in 70+ locations, with the expected OpenVPN, L2TP/IPSec, IKEv2, KeepSolid Wise, and PPTP protocols. VPN Unlimited provides clients for Windows, Linux, macOS, iOS, Android, Windows Phone and even browser extensions for Firefox and Chrome.
With so many options to keep your browsing safe and private, and a top deals, VPN Unlimited have you covered.
One of the most popular VPN services out there, ExpressVPN currently offers a 15-month deal with three months free, exclusive to MakeUseOf readers. This costs just $99.95, which works out at $6.67 a month. A flat monthly subscription is $12.95, so you’re looking at a 49 percent savings on our recommended VPN.
Based in the British Virgin Islands, ExpressVPN is not bound by any data retention laws, so your online activity is not logged. With support for defeating geo-location, torrenting, Tor access, and gaming, ExpressVPN has over 1,000 servers across 87 countries worldwide. It’s fast, too.
While not the cheapest VPN option, ExpressVPN’s reputation is solid, offering apps for every desktop and mobile platform, and support for routers. You’ll even browser plugins for Chrome, Firefox, and Safari. Keen to protect your privacy, ExpressVPN accepts payment Bitcoin, along with credit card, PayPal, and various other methods.
On reviewing ExpressVPN, we declared it “…a solid, secure, speedy VPN service, with a good bunch of features available along a standard price band […] multi-platform support and logless servers.”
VPN deals are fantastic, as they really make it easy for you to get started with keeping your online activity private from hackers and trackers. What also helps is easy to use apps, and HotSpot Shield certainly keeps things simple.
Ideal for overcoming Netfix geo-location restrictions, with high speeds, logless usage, and torrent support, HotSpot Shield has apps for Windows, macOS, Android, iOS, and the Chrome browser.
Subscriptions for HotSpot Shield start at $12.99 a month, but by paying upfront you can save an immense 76 percent over two years. This offer of $71.76 is HotSpot Shield’s best offer and boils down to a tiny $2.99 a month. Better still, you get to keep this price when the account is rebilled after 24 months.
Our review of HotSpot Shield concluded that its “simple user interface is also a massive benefit, making it so easy to switch between VPN servers.”
If you’ve been looking for a VPN, you’ve probably heard of TunnelBear. While some VPN services are a little difficult to use, TunnelBear is easy to set up and use. But what is it, and how much does it cost?
Available for Windows, macOS, iPhone, and Android, TunnelBear has a simple privacy policy and does not collect usage logs. This will help enhance your privacy further while connecting to the web via a VPN.
While the VPN can be used to circumvent geo-blocking, TunnelBear sadly does not offer support for torrenters.
While Tunnelbear has a useful free option, it is limited to 500MB of data per month. Right now, it has a 58 percent discount on offer, so if you pay $49.99 per year, Tunnelbear’s service works out at just $4.17 a month. There’s also a $9.99 monthly package if you prefer not to sign up long-term.
As noted in our review, “TunnelBear’s approach […] brings easy, affordable privacy and peace-of-mind to users around the world.”
A torrent-friendly VPN service, Private Internet Access offers a good $6.95 basic monthly deal, but if you want to pay even less, you can get an amazing 58% discount! Simply use the two-year option and pay $69.95 up front—this equates to a tiny $2.91 a month.
Private Internet Access offers support for five simultaneous device connections, blocks trackers and malware, and no traffic logs are retained, thus enhancing your privacy online.
One of the fastest VPNs available, Buffered has all of the expected features (256-bit encryption, geo-restriction bypass, multiple device support) and is based in Gibraltar, which places it beyond the “14 Eyes” alliance of international surveillance.
Buffered is speedier than other VPNs thanks to 45 superfast servers positioned around the globe. This is significant as many VPNs can slow down your online access.
With apps for Windows, Linux, Mac, iOS, and Android, and with support for routers, Buffered’s best payment plan works out at just $7.62 a month for 13 months with a $99 up-front payment. That’s a 41 percent saving, on the basic $12.99 monthly plan!
7 Great Low-Cost VPN Deals!
VPN providers regularly offer great deals to entice new customers, so it can be difficult to judge which services to use. We’re confident that you’ll be impressed with the VPNs and deals listed here:
We’re certain that you’ll find a VPN that matches your requirements and budgets. If not, try looking further afield. Our top list of the best VPN services is a good place to start.
Ever since the E.U. voted to bring in compulsory cookie warnings in 2012, the small browser-based files have never been far from people’s minds.
But not all cookies are born equal. In fact, there are lots of different types of cookies out there. Some are good, some are bad. Let’s take a closer look.
1. Session Cookies
Imagine trying to shop on Amazon if you couldn’t fill your cart until you were ready to check out. You’d have to remember all the items you wanted to buy as you browsed the site.
Without session cookies, that situation would be a reality.
It’s easiest to think of session cookies as a website’s short-term memory. They let sites recognize you as you move from page to page within their domain. Without the session cookies, you’d be treated as a new visitor every time you clicked on a new internal link.
They do not collect any information about your computer, and they contain no personally identifiable information that can link a session to a particular user.
Session cookies are temporary; when you close your browser, your computer will automatically delete them all.
2. First-Party Cookies
Also known as persistent cookies, permanent cookies, and stored cookies, first-party cookies are akin to a website’s long-term memory. They help sites to remember your information and settings when you revisit them in the future.
Without these cookies, sites would not be able to remember your preferences such as menu settings, themes, language selection, and internal bookmarks between sessions. With first-party cookies, you can make those selections on your first visit and they will be consistent until the cookie expires.
Most persistent cookies expire after one or two years. If you do not visit the site within the expiration time frame, your browser will delete the cookie. You can also remove them manually.
First-party cookies also play an important role in user authentication. If you were to disable them, you would need to re-enter your login credentials every time you visited a page.
On the downside, companies can use persistent cookies to track you. Unlike session cookies, they do record information about your browsing habits for the entire time that they are active.
3. Third-Party Cookies
Third-party cookies are the bad guys. They are the reason that cookies have such a bad reputation among internet users.
Let’s take a step back. In the case of first-party cookies, a cookie’s domain will match the domain of the site you’re visiting. A third-party cookie originates from a different domain.
Because it is not coming from the site you’re looking at, a third-party cookie is not providing any of the benefits of session cookies and first-party cookies that we just discussed.
Instead, it has one sole focus—to track you. The tracking can take many forms; the cookies can learn about your browsing history, online behavior, demographics, spending habits, and more.
Because of their ability to track, third-party cookies have become a favorite of advertising networks in a bid to drive up their sales and pageviews.
Today, most browsers provide a straightforward way of blocking third-party cookies. We strongly recommend that you take the necessary steps in your browser of choice.
If you’re using Chrome, go to More > Settings > Advanced > Privacy and Security > Content Settings > Cookies > Block Third-Party Cookies.
4. Secure Cookies
The three types of cookies we’ve covered so far are the most well-known and the most common. But there are a few others you need to be aware of.
The first is a secure cookie. It can only be transmitted over an encrypted connection. Typically, that means HTTPS.
As long as the cookie’s “Secure” attribute is active, the user agent will not transmit the cookie over an unencrypted channel. Without the Secure flag, the cookie is sent in clear text and can be intercepted by unauthorized third-parties.
However, even with the Secure flag, developers should not use a cookie to store sensitive information. In practice, the flag only protects a cookie’s confidentiality. A network attacker could overwrite secure cookies from an insecure connection. This is especially true if a site has both an HTTP and HTTPS version.
5. HTTP-Only Cookies
Secure cookies are often also HTTP-only cookies. The two flags work in tandem to help to reduce a cookie’s vulnerability to a cross-site scripting (XSS) attack.
In an XSS attack, a hacker injects malicious code into trusted websites. A browser cannot tell that the script should not be trusted. Therefore, the script can access the browser’s data about the infected site, including cookies.
A secure cookie cannot be accessed by scripting languages (like JavaScript), thus protecting it against such attacks.
6. Flash Cookies
A Flash cookie is the most common type of supercookie. In case you’re not aware, a supercookie performs many of the same functions as a regular cookie, but they are more difficult to find and delete.
In the case of Flash cookies, developers use the Flash plugin to hide cookies from your browser’s native cookie management tools.
Flash cookies are available to all browsers (so using one browser for your credit card and one for downloading torrents would have negligible security benefits). They can hold 100KB of data compared to an HTTP cookies’ mere 4KBb.
A zombie cookie is closely tied to a Flash cookie. A zombie cookie can instantly recreate itself if someone deletes it. The recreation is possible thanks to backups stored outside a browser’s regular cookie storage folder—often as a Flash Local Shared Object or as HTML5 Web Storage.
The recreation relies on Quantcast technology. Because Flash cookie stores a unique user ID in Adobe Flash player’s storage bin, Quantcast can reapply it to a new HTTP cookie if the old one is removed.
Learn How to Manage Your Cookies
It’s important to realize that not all cookies are bad. Without them, the web would not be able to function in the way we have come to expect.
Googleannounced today it’s now using mobile-first indexing for over half the web pages shown in its search results globally – a significant milestone in Google’s move to favor mobile sites over desktop sites in its search results.
The plans for the project have been in the works for years.
The company had first detailed its efforts around mobile-first indexing back in 2016, where it explained the impacts to how its search index operates. It said it would shift over to using the mobile version of a website’s content to index its pages, as well as to understand its structured data and show snippets from the site in Google’s search results.
Its reasoning behind the change is simple: most people today search Google from a mobile device, not a desktop computer. But Google’s ranking systems for the web were originally built for the desktop era. They still typically look at the desktop version of the page’s content to determine its relevance to the user.
This, obviously, causes problems when the desktop site and the mobile site are not in sync.
Before responsive web design became more commonplace, many site owners built a separate, simpler and sometimes less informative version of their site for their mobile web visitors. These users may have been guided to the site because of Google Search. But once there, they couldn’t find what they were looking for because it was only available on the desktop version of the web page.
Earlier this year, Google announced it had begun to officially roll out its “mobile-first” indexing of the web, following a year and a half of testing and experimentation. At the time, it said it would first move over the sites already following the best practices for mobile-first indexing. It also noted it would favor the site’s own mobile version of its webpage over Google’s fast-loading AMP pages.
Sites who are shifted are notified through a message in Search Console and then see increased visits from the smartphone version of Googlebot, which crawls the mobile version of their site. Site owners can also check their server logs, where they can track the increased requests from Googlebot Smartphone.
Google additionally offers a URL inspection tool, which site owners can use to check how a URL from their site – like the homepage – was last crawled and indexed.
Google today notes that sites that don’t use responsive web design are seeing two common problems when Google tries to move them over to mobile-first indexing.
Some don’t use structured data on their mobile sites, even though they use it on the desktop. This is important because it helps Google to understand the website’s content and allows it to highlight pages’ content in its search results, through its “fancier” features like rich results, Knowledge Graph results, enhanced search results, carousels and more – basically any time you see more engaging search results that offer more than just a list of blue links.
The company also said that some mobile sites were missing alt-text for images, which makes it harder for Google to understand the images’ content.
At the time of the initial wave of sites being shifted over, Google had said that the mobile-friendly index wouldn’t directly impact how content is ranked, but it did say that a site’s mobile-friendly content will help it “perform better” in mobile search results. Mobile-friendliness has also long been one of many factors in determining how a site is ranked, but it’s not the only one.
Google didn’t say what it will do to sites that are never properly updated for the mobile web, but it seems that – at some point – their ranking could be impacted.
Googleannounced today it’s now using mobile-first indexing for over half the web pages shown in its search results globally – a significant milestone in Google’s move to favor mobile sites over desktop sites in its search results.
The plans for the project have been in the works for years.
The company had first detailed its efforts around mobile-first indexing back in 2016, where it explained the impacts to how its search index operates. It said it would shift over to using the mobile version of a website’s content to index its pages, as well as to understand its structured data and show snippets from the site in Google’s search results.
Its reasoning behind the change is simple: most people today search Google from a mobile device, not a desktop computer. But Google’s ranking systems for the web were originally built for the desktop era. They still typically look at the desktop version of the page’s content to determine its relevance to the user.
This, obviously, causes problems when the desktop site and the mobile site are not in sync.
Before responsive web design became more commonplace, many site owners built a separate, simpler and sometimes less informative version of their site for their mobile web visitors. These users may have been guided to the site because of Google Search. But once there, they couldn’t find what they were looking for because it was only available on the desktop version of the web page.
Earlier this year, Google announced it had begun to officially roll out its “mobile-first” indexing of the web, following a year and a half of testing and experimentation. At the time, it said it would first move over the sites already following the best practices for mobile-first indexing. It also noted it would favor the site’s own mobile version of its webpage over Google’s fast-loading AMP pages.
Sites who are shifted are notified through a message in Search Console and then see increased visits from the smartphone version of Googlebot, which crawls the mobile version of their site. Site owners can also check their server logs, where they can track the increased requests from Googlebot Smartphone.
Google additionally offers a URL inspection tool, which site owners can use to check how a URL from their site – like the homepage – was last crawled and indexed.
Google today notes that sites that don’t use responsive web design are seeing two common problems when Google tries to move them over to mobile-first indexing.
Some don’t use structured data on their mobile sites, even though they use it on the desktop. This is important because it helps Google to understand the website’s content and allows it to highlight pages’ content in its search results, through its “fancier” features like rich results, Knowledge Graph results, enhanced search results, carousels and more – basically any time you see more engaging search results that offer more than just a list of blue links.
The company also said that some mobile sites were missing alt-text for images, which makes it harder for Google to understand the images’ content.
At the time of the initial wave of sites being shifted over, Google had said that the mobile-friendly index wouldn’t directly impact how content is ranked, but it did say that a site’s mobile-friendly content will help it “perform better” in mobile search results. Mobile-friendliness has also long been one of many factors in determining how a site is ranked, but it’s not the only one.
Google didn’t say what it will do to sites that are never properly updated for the mobile web, but it seems that – at some point – their ranking could be impacted.
The latest revelations about Facebook’s handling of user data — an investigation by the New York Timesfound that Facebook had been providing special data access to large companies like Amazon, Microsoft, Spotify and others — has landed the social network once more in hot water in Europe, and specifically the United Kingdom.
Today, Damian Collins MP, Chair of the Digital, Culture, Media and Sport Committee, issued a statement in which he called on competition authorities to open an investigation into abusive market dominance, and also for Facebook to once again appear before his committee to “explain how their policies work on access to user data, and whether policies are a breach of data privacy law, as it would appear that user data was made available to firms without the informed consent of the user having been given.”
Specifically, Collins is focusing on the fact that the report published early today appears to contradict Facebook’s previous testimony.
“I feel that we have been given misleading responses by the company when we have asked these questions during previous evidence sessions,” Collins said in the statement. The full statement is below.
The DCMS has hauled Facebook in for questioning multiple times now over to its ongoing investigation into how Facebook provides access to and safeguards (or doesn’t as the case may be) user data. Previous requests (hereand here) have also specifically asked for Mark Zuckerberg, the co-founder, chairman and CEO of Facebook, to appear, although he has yet to do so.
While the statement from Collins doesn’t make mention of it, there are other angles to be explored as well. Earlier this month, LinkedIn was singled out for how it leveraged Facebook’s ad platform to gather information about users’ friends for LinkedIn marketing and networking purposes, and a report in Gizmodoalso published yesterday highlights how that this kind of cross-pollination is/was rife among several other players too. This is likely also to come up in subsequent investigations.
The bottom line is that while these may not be API loopholes along the lines of those exploited by Cambridge Analytica, they all point to just how tangled and intentionally confusing a lot of these relationships are, obscuring just how much information about us is known and used.
The competition authority reference, meanwhile, is linked with the fact that Facebook appeared to give preferential access to user data to larger companies over smaller ones — in fact, cutting smaller companies out of the equation altogether.
Irrespective of whether it was appropriate data access or not (Facebook, of course, argues that each specific dealhad a purpose that did not violate user privacy), there are questions here about whether Facebook abused its market-dominating position in social media by favoring large companies over smaller ones in forging partnerships or providing access to services.
To be clear, Facebook has not been deemed a monopoly by any authorities — although there are investigations underway both in Washingtonand Germanythat are considering whether Facebook could and should be investigated as such. In that context, Collins appeal to competition authorities appears to be a step in the long process of determining whether there are grounds for investigating on that front, and my suspicion is that this is not the last you will year of this.
“The Competition authorities should also investigate how Facebook decides which companies have access to user data and which don’t,” Collins said. “Given the dominant market position they enjoy in social media, this gives real concerns about whether they are behaving as a monopoly, exercising their considerable power to further dominate the commercial environment in which they trade; making some businesses, and breaking others in the process.”
All in all, this is a damning development for the social network — which has over 2 billion users and is fighting fires on other fronts— in its relations with authorities and regulators, one that will continue to erode the company’s reputation with them and users alike.
The full text of Collins’ statement is below:
“This latest investigation adds to the evidence published earlier this month by the DCMS select Committee, from documents we received from the American app developer, Six4Three.
“The investigation shows that Facebook offers preferential access to user data to some of its major corporate partners. The scale of the business these companies do with Facebook underpins the value their relationship. Facebook rewards these firms with data privileges that other organisations to not enjoy.
“We have to seriously challenge the claim by Facebook that they are not selling user data. They may not be letting people take it away by the bucket load, but they do reward companies with access to data that others are denied, if they place a high value on the business they do together. This is just another form of selling. We remain concerned as well about Facebook’s ability to police what happens to user data when it is shared with developers, as was highlighted by the Cambridge Analytica data breach.
“Facebook should come back in front of the Committee to explain how their policies work on access to user data, and whether policies are a breach of data privacy law, as it would appear that user data was made available to firms without the informed consent of the user having been given. I feel that we have been given misleading responses by the company when we have asked these questions during previous evidence sessions.
“The Competition authorities should also investigate how Facebook decides which companies have access to user data and which don’t. Given the dominant market position they enjoy in social media, this gives real concerns about whether they are behaving as a monopoly, exercising their considerable power to further dominate the commercial environment in which they trade; making some businesses, and breaking others in the process.”
The G-Shock is so nerdy that it’s become cool and this latest model, the GMWB5000GD-9, is no exception. Based on the original G-Shock models, this decidedly unsmart (but not dumb) watch features solar charging, atomic timekeeping, and a simple Bluetooth connection to your phone. Plus now it comes in gold or silver toned metal, a decided departure for the decades-old brand.
This wild redesign takes cues from a solid-gold prototype designed by Casio’s Ibe Kikuo. That blinged out watch, which could hit the market but will be as expensive as an entire Casio display case, is a bit much. However, these two steel models are quite exciting and very luxe.
“Inspired by the first G-SHOCK model, DW5000C, this upgraded original boasts a modern, lustrous, color way while maintaining a vintage aesthetic,” writes Casio. “The watch also incorporates one of the first and most iconic G-SHOCK case designs, featuring a vintage, square shape case, and bezel with a brick pattern on the face and gorgeous gold color accent.”
At $550 this is a bit pricey for an entry-level quartz watch but rest assured it will find a foothold in the fashion world as “dorky” becomes even more synonymous with “cat-walk ready.”
As Facebook colonized the rest of the web with its functionality in hopes of fueling user growth, it built aggressive integrations with partners that are coming under newfound scrutiny through a deeply reported New York Times investigation. Some of what Facebook did was sloppy or unsettling, including forgetting to shut down APIs when it cancelled its Instant Personalization feature for other sites in 2014, and how it used contact syncing to power friend recommendations.
But other moves aren’t as bad as they sound. Facebook did provide Spotify and Netflix the ability to access users messages, but only so people could send friends songs or movies via Facebook messages without leaving those apps. And Facebook did let Yahoo and Blackberry access people’s News Feeds, but to let users browse those feeds within social hub features inside those apps. These partners could only access data when users logged in and connected their Facebook accounts, and were only approved to use this data to provide Facebook-related functionality. That means Spotify at least wasn’t supposed to be rifling through everyone’s messages to find out what bands they talk about so it could build better curation algorithms, and there’s no evidence yet that it did.
Thankfully Facebook has ditched most of these integrations, as the dominance of iOS and Android have allowed it to build fewer, more standardized, and better safeguarded access points to its data. And it’s battened down the hatches in some ways, forcing users to shortcut from Spotify into the real Facebook Messenger rather than giving third-parties any special access to offer Facebook Messaging themselves.
The most glaring allegation Facebook hasn’t adequately responded to yet is that it used data from Amazon, Yahoo, and Huawei to improve friend suggestions through People You May Know — perhaps its creepiest feature. The company needs to accept the loss of growth hacking trade secrets and become much more transparent about how it makes so uncannily accurate recommendations of who to friend request — as Gizmodo’s Kashmir Hill has documented.
In some cases, Facebook has admitted to missteps, with its Director of Developer Platforms and Programs Konstantinos Papamiltiadis writing “we shouldn’t have left the APIs in place after we shut down instant personalization.”
In others, we’ll have decide where to draw the line between what was actually dangerous and what gives us the chills at first glance. You don’t ask permission from friends to read an email from them on a certain browser or device, so should you worry if they saw your Facebook status update on a Blackberry social hub feature instead of the traditional Facebook app? Well that depends on how the access is monitored and meted out.
The underlying question is whether we trust that Facebook and these other big tech companies actually abided by rules to oversee and not to overuse data. Facebook has done plenty wrong, and after repeatedly failing to be transparent or live up to its apologies, it doesn’t deserve the benefit of the doubt. For that reason, I don’t want it giving any developer — even ones I normally trust like Spotify — access to sensitive data protected merely by their promise of good behavior despite financial incentives for misuse.
Facebook’s former chief security officer Alex Stamos tweeted that “allowing for 3rd party clients is the kind of pro-competition move we want to see from dominant platforms. For ex, making Gmail only accessible to Android and the Gmail app would be horrible. For the NY Times to try to scandalize this kind of integration is wrong.” But countered that by noting that “integrations that are sneaky or send secret data to servers controlled by others really is wrong.”
Even if Spotify and Netflix didn’t abuse the access Facebook provided, there’s always eventually a Cambridge Analytica. Tech companies have proven their word can’t necessarily be trusted. The best way to protect users is to properly lock down the platforms with ample vetting, limits, and oversight so there won’t be gray areas that require us to put our faith in the kindness of businesses.
As Facebook colonized the rest of the web with its functionality in hopes of fueling user growth, it built aggressive integrations with partners that are coming under newfound scrutiny through a deeply reported New York Times investigation. Some of what Facebook did was sloppy or unsettling, including forgetting to shut down APIs when it cancelled its Instant Personalization feature for other sites in 2014, and how it used contact syncing to power friend recommendations.
But other moves aren’t as bad as they sound. Facebook did provide Spotify and Netflix the ability to access users messages, but only so people could send friends songs or movies via Facebook messages without leaving those apps. And Facebook did let Yahoo and Blackberry access people’s News Feeds, but to let users browse those feeds within social hub features inside those apps. These partners could only access data when users logged in and connected their Facebook accounts, and were only approved to use this data to provide Facebook-related functionality. That means Spotify at least wasn’t supposed to be rifling through everyone’s messages to find out what bands they talk about so it could build better curation algorithms, and there’s no evidence yet that it did.
Thankfully Facebook has ditched most of these integrations, as the dominance of iOS and Android have allowed it to build fewer, more standardized, and better safeguarded access points to its data. And it’s battened down the hatches in some ways, forcing users to shortcut from Spotify into the real Facebook Messenger rather than giving third-parties any special access to offer Facebook Messaging themselves.
The most glaring allegation Facebook hasn’t adequately responded to yet is that it used data from Amazon, Yahoo, and Huawei to improve friend suggestions through People You May Know — perhaps its creepiest feature. The company needs to accept the loss of growth hacking trade secrets and become much more transparent about how it makes so uncannily accurate recommendations of who to friend request — as Gizmodo’s Kashmir Hill has documented.
In some cases, Facebook has admitted to missteps, with its Director of Developer Platforms and Programs Konstantinos Papamiltiadis writing “we shouldn’t have left the APIs in place after we shut down instant personalization.”
In others, we’ll have decide where to draw the line between what was actually dangerous and what gives us the chills at first glance. You don’t ask permission from friends to read an email from them on a certain browser or device, so should you worry if they saw your Facebook status update on a Blackberry social hub feature instead of the traditional Facebook app? Well that depends on how the access is monitored and meted out.
The underlying question is whether we trust that Facebook and these other big tech companies actually abided by rules to oversee and not to overuse data. Facebook has done plenty wrong, and after repeatedly failing to be transparent or live up to its apologies, it doesn’t deserve the benefit of the doubt. For that reason, I don’t want it giving any developer — even ones I normally trust like Spotify — access to sensitive data protected merely by their promise of good behavior despite financial incentives for misuse.
Facebook’s former chief security officer Alex Stamos tweeted that “allowing for 3rd party clients is the kind of pro-competition move we want to see from dominant platforms. For ex, making Gmail only accessible to Android and the Gmail app would be horrible. For the NY Times to try to scandalize this kind of integration is wrong.” But countered that by noting that “integrations that are sneaky or send secret data to servers controlled by others really is wrong.”
Even if Spotify and Netflix didn’t abuse the access Facebook provided, there’s always eventually a Cambridge Analytica. Tech companies have proven their word can’t necessarily be trusted. The best way to protect users is to properly lock down the platforms with ample vetting, limits, and oversight so there won’t be gray areas that require us to put our faith in the kindness of businesses.
Twitter has finally resolved an issue that has been annoying its users for years. Tweets used to be presented in purely chronological order, with the newest at the top. But then Twitter decided to start ranking tweets according to its own algorithms.
In September 2018, Twitter promised to bring back the chronological timeline. Since then, the social network has been working on a way of letting users switch between a chronological timeline and a algorithmically ranked timeline. And it’s finally ready.
Twitter Launches the “Sparkle”
Twitter now offers a digital switch allowing users to swap between a chronological timeline and a ranked timeline. The chronological timeline shows every tweet from the people you follow in reverse order, while the ranked timeline places selected tweets higher.
You can switch between the two using what Twitter calls the “sparkle”. This is a sparkly icon that sits in the top right of your screen above your timeline. Individual users can click this at will to switch between a chronological timeline and a ranked timeline.
New on iOS! Starting today, you can tap ? to switch between the latest and top Tweets in your timeline. Coming soon to Android. pic.twitter.com/6B9OQG391S
Twitter is still treating the ranked timeline as the default option, referring to that as “Home”. The chronological timeline is being treated as the alternative option, but as long as it’s an option open to all users, we’re not going to complain.
The “sparkle” is rolling out on iOS first, with Twitter promising it will be coming to other platforms, including Android, over the coming weeks. So if you can’t see the “sparkle” quite yet just keep checking for updates to the Twitter app.
Switching Between Twitter Timelines
This is a really sensible way of dealing with users demanding the return of the chronological timeline. It’s Twitter acknowledging users’ desire to see all tweets from everyone they follow, while retaining the option to show people the best tweets first.
Twitter is still far from perfect. Not only is it confusing for new users, it seems to bring the worst out in a lot of people. Still, it’s one of the best ways of keeping up with what’s happening in the world, and our guide to using Twitter should help you tame the beast.
By any measure Facebook hasn’t had the best of years in 2018.
But while toxic problems keep piling up and, well, raining acidly down on the social networking giant — from election interference, to fake accounts, faulty metrics, security flaws, ethics failures, privacy outrages and much more besides — the silver lining of having a core business now widely perceived as hostile to democratic processes and civilized sentiment, and the tool of choice for shitposters agitating for hate and societal division, well, everywhere in the world, is that Facebook has frankly far more important things to worry about than the latest anti-tech-industry salvo from President Trump.
In an early morning tweet today, Trump (again) attacked what he dubbed anti-conservative “bias” in the digital social sphere — hitting out at not just Facebook but tech’s holy trinity of social giants, with a claim that “Facebook, Twitter and Google are so biased towards the Dems it is ridiculous!”
Facebook, Twitter and Google are so biased toward the Dems it is ridiculous! Twitter, in fact, has made it much more difficult for people to join @realDonaldTrump. They have removed many names & greatly slowed the level and speed of increase. They have acknowledged-done NOTHING!
Time was when Facebook was so sensitive to accusations of internal anti-conservative bias that it fired a bunch of journalists it had contracted and replaced them with algorithms — which almost immediately pumped up a bunch of fake news. RIP irony.
Not today, though.
When asked if it had a response to Trump’s accusation of bias a Facebook spokesperson told us: “We don’t have anything to add here.”
The brevity and alacrity of the response suggested the spokesperson had a really cheerful expression on their face when they typed it.
The relief of Facebook not having to give a shit this time was kinda palpable, even in pixel form.
It was also a far cry from the screeds the company routinely dispenses these days to try to muffle journalistic — and indeed political — enquiry.
Trump evidently doesn’t factor ‘bigly’ on Facebook’s oversubscribed risk-list.
Even though Facebook was the first name on the president’s (non-alphabetical) tech giant hit-list.
Still, Twitter appeared to have irked Trump more, as his tweet singled out the short-form platform — with an accusation that Twitter has made it “much more difficult for people to join [sic] @realDonaldTrump”. (We think by “join” he means follow. But we’re speculating wildly.)
This is perhaps why Twitter felt moved to provide a response to the claim of bias, albeit also without wasting a lot of words.
Here’s its statement:
Our focus is on the health of the service, and that includes work to remove fake accounts to prevent malicious behavior. Many prominent accounts have seen follower counts drop, but the result is higher confidence that the followers they have are real, engaged people.
Presumably the president failed to read our report, from July, when we trailed Twitter’s forthcoming spam purge, warning it would result in users with lots of followers taking a noticeable hit in the coming days. In a word: Sad.
Of course we also asked Google for a response to Trump’s bias claim. But just got radio silence.
In similar “bias” tweets from August the company got a bigger Trump-lashing. And in a response statement then it told us: “We never rank search results to manipulate political sentiment.”
By any measure Facebook hasn’t had the best of years in 2018.
But while toxic problems keep piling up and, well, raining acidly down on the social networking giant — from election interference, to fake accounts, faulty metrics, security flaws, ethics failures, privacy outrages and much more besides — the silver lining of having a core business now widely perceived as hostile to democratic processes and civilized sentiment, and the tool of choice for shitposters agitating for hate and societal division, well, everywhere in the world, is that Facebook has frankly far more important things to worry about than the latest anti-tech-industry salvo from President Trump.
In an early morning tweet today, Trump (again) attacked what he dubbed anti-conservative “bias” in the digital social sphere — hitting out at not just Facebook but tech’s holy trinity of social giants, with a claim that “Facebook, Twitter and Google are so biased towards the Dems it is ridiculous!”
Facebook, Twitter and Google are so biased toward the Dems it is ridiculous! Twitter, in fact, has made it much more difficult for people to join @realDonaldTrump. They have removed many names & greatly slowed the level and speed of increase. They have acknowledged-done NOTHING!
Time was when Facebook was so sensitive to accusations of internal anti-conservative bias that it fired a bunch of journalists it had contracted and replaced them with algorithms — which almost immediately pumped up a bunch of fake news. RIP irony.
Not today, though.
When asked if it had a response to Trump’s accusation of bias a Facebook spokesperson told us: “We don’t have anything to add here.”
The brevity and alacrity of the response suggested the spokesperson had a really cheerful expression on their face when they typed it.
The relief of Facebook not having to give a shit this time was kinda palpable, even in pixel form.
It was also a far cry from the screeds the company routinely dispenses these days to try to muffle journalistic — and indeed political — enquiry.
Trump evidently doesn’t factor ‘bigly’ on Facebook’s oversubscribed risk-list.
Even though Facebook was the first name on the president’s (non-alphabetical) tech giant hit-list.
Still, Twitter appeared to have irked Trump more, as his tweet singled out the short-form platform — with an accusation that Twitter has made it “much more difficult for people to join [sic] @realDonaldTrump”. (We think by “join” he means follow. But we’re speculating wildly.)
This is perhaps why Twitter felt moved to provide a response to the claim of bias, albeit also without wasting a lot of words.
Here’s its statement:
Our focus is on the health of the service, and that includes work to remove fake accounts to prevent malicious behavior. Many prominent accounts have seen follower counts drop, but the result is higher confidence that the followers they have are real, engaged people.
Presumably the president failed to read our report, from July, when we trailed Twitter’s forthcoming spam purge, warning it would result in users with lots of followers taking a noticeable hit in the coming days. In a word: Sad.
Of course we also asked Google for a response to Trump’s bias claim. But just got radio silence.
In similar “bias” tweets from August the company got a bigger Trump-lashing. And in a response statement then it told us: “We never rank search results to manipulate political sentiment.”
Years ago, Google’s Street View program expanded from streets to virtually everywhere, thanks to Google’s Trekker program that put 360-degree Street View cameras into a single backpack. Today, Google announced its upgraded Trekker backpack, which is significantly smaller and lighter than before. The old one weighed in at about 44 pounds.
It’s not just a new design, though — Google also notes that the new Trekker features improved hardware that will allow it to capture better and sharper imagery, thanks to higher-resolution sensors and an increased aperture.
“Like previous Trekker generations, the new version can be put on cars, boats or even zip lines,” the company explains. “This helps when capturing hard-to-access places, or when building maps for developing countries and cities with complex structures.”
While you probably can’t just get a Trekker to map out your garden, Google notes that it continues to run its Trekker loan program. This program is open to organizations like tourism boards, nonprofits, government agencies, universities and research groups.
Chances are, you’ll see some improved Street View imagery from hard to reach places on Google Maps soon. Until then, you can go ahead and take a virtual stroll through Petra or across the beaches of Christmas Island.



 “From our survey – and more comprehensive analyses like the
“From our survey – and more comprehensive analyses like the 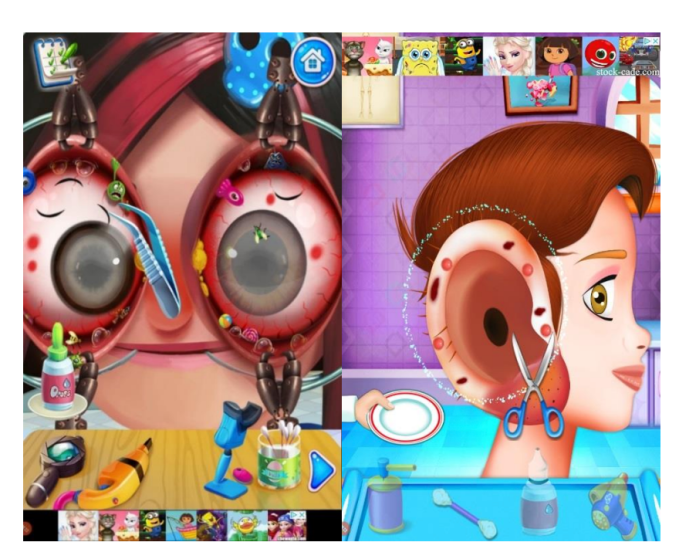














 It’s not just a new design, though — Google also notes that the new Trekker features improved hardware that will allow it to capture better and sharper imagery, thanks to higher-resolution sensors and an increased aperture.
It’s not just a new design, though — Google also notes that the new Trekker features improved hardware that will allow it to capture better and sharper imagery, thanks to higher-resolution sensors and an increased aperture.

