Before the pandemic, more than 40% of new internet users were children. Estimates now suggest that children’s screen time has surged by 60% or more with children 12 and under spending upward of five hours per day on screens (with all of the associated benefits and perils).
Although it’s easy to marvel at the technological prowess of digital natives, educators (and parents) are painfully aware that young “remote learners” often struggle to navigate the keyboards, menus and interfaces required to make good on the promise of education technology.
Against that backdrop, voice-enabled digital assistants hold out hope of a more frictionless interaction with technology. But while kids are fond of asking Alexa or Siri to beatbox, tell jokes or make animal sounds, parents and teachers know that these systems have trouble comprehending their youngest users once they deviate from predictable requests.
The challenge stems from the fact that the speech recognition software that powers popular voice assistants like Alexa, Siri and Google was never designed for use with children, whose voices, language and behavior are far more complex than that of adults.
It is not just that kid’s voices are squeakier, their vocal tracts are thinner and shorter, their vocal folds smaller and their larynx has not yet fully developed. This results in very different speech patterns than that of an older child or an adult.
From the graphic below it is easy to see that simply changing the pitch of adult voices used to train speech recognition fails to reproduce the complexity of information required to comprehend a child’s speech. Children’s language structures and patterns vary greatly. They make leaps in syntax, pronunciation and grammar that need to be taken into account by the natural language processing component of speech recognition systems. That complexity is compounded by interspeaker variability among children at a wide range of different developmental stages that need not be accounted for with adult speech.
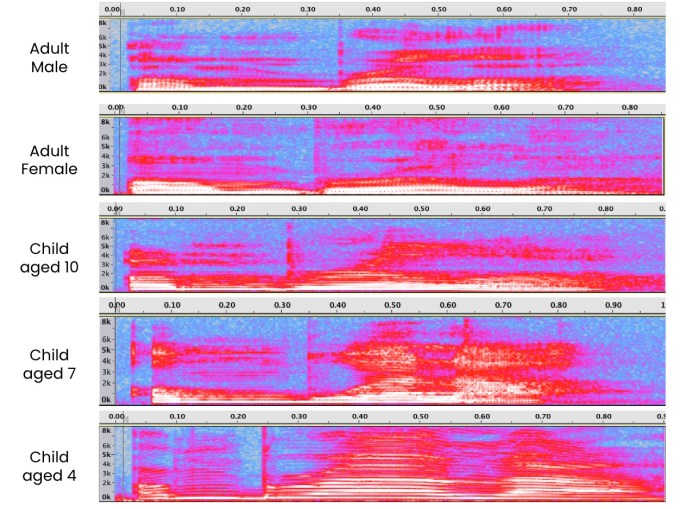
Changing the pitch of adult voices used to train speech recognition fails to reproduce the complexity of information required to comprehend a child’s speech. Image Credits: SoapBox Labs
A child’s speech behavior is not just more variable than adults, it is wildly erratic. Children over-enunciate words, elongate certain syllables, punctuate each word as they think aloud or skip some words entirely. Their speech patterns are not beholden to common cadences familiar to systems built for adult users. As adults, we have learned how to best interact with these devices, how to elicit the best response. We straighten ourselves up, we formulate the request in our heads, modify it based on learned behavior and we speak our requests out loud, inhale a deep breath … “Alexa … ” Kids simply blurt out their unthought out requests as if Siri or Alexa were human, and more often than not get an erroneous or canned response.
In an educational setting, these challenges are exacerbated by the fact that speech recognition must grapple with not just ambient noise and the unpredictability of the classroom, but changes in a child’s speech throughout the year, and the multiplicity of accents and dialects in a typical elementary school. Physical, language and behavioral differences between kids and adults also increase dramatically the younger the child. That means that young learners, who stand to benefit most from speech recognition, are the most difficult for developers to build for.
To account for and understand the highly varied quirks of children’s language requires speech recognition systems built to intentionally learn from the ways kids speak. Children’s speech cannot be treated simply as just another accent or dialect for speech recognition to accommodate; it’s fundamentally and practically different, and it changes as children grow and develop physically as well as in language skills.
Unlike most consumer contexts, accuracy has profound implications for children. A system that tells a kid they are wrong when they are right (false negative) damages their confidence; that tells them they are right when they are wrong (false positive) risks socioemotional (and psychometric) harm. In an entertainment setting, in apps, gaming, robotics and smart toys, these false negatives or positives lead to frustrating experiences. In schools, errors, misunderstanding or canned responses can have far more profound educational — and equity — implications.
Well-documented bias in speech recognition can, for example, have pernicious effects with children. It is not acceptable for a product to work with poorer accuracy — delivering false positives and negatives — for kids of a certain demographic or socioeconomic background. A growing body of research suggests that voice can be an extremely valuable interface for kids but we cannot allow or ignore the potential for it to magnify already endemic biases and inequities in our schools.
Speech recognition has the potential to be a powerful tool for kids at home and in the classroom. It can fill critical gaps in supporting children through the stages of literacy and language learning, helping kids better understand — and be understood by — the world around them. It can pave the way for a new era of “invisible” observational measures that work reliably, even in a remote setting. But most of today’s speech recognition tools are ill-suited to this goal. The technologies found in Siri, Alexa and other voice assistants have a job to do — to understand adults who speak clearly and predictably — and, for the most part, they do that job well. If speech recognition is to work for kids, it has to be modeled for, and respond to, their unique voices, language and behaviors.



Read Full Article
No comments:
Post a Comment