Most marketers believe there’s a lot of value in having relevant, engaging images featured in content.
But selecting the “right” images for blog posts, social media posts or video thumbnails has historically been a subjective process. Social media and SEO gurus have a slew of advice on picking the right images, but this advice typically lacks real empirical data.
This got me thinking: Is there a data-driven — or even better, an AI-driven — process for gaining deeper insight into which images are more likely to perform well (aka more likely to garner human attention and sharing behavior)?
The technique for finding optimal photos
In July of 2019, a fascinating new machine learning paper called “Intrinsic Image Popularity Assessment” was published. This new model has found a reliable way to predict an image’s likely “popularity” (estimation of likelihood the image will get a like on Instagram).
It also showed an ability to outperform humans, with a 76.65% accuracy on predicting how many likes an Instagram photo would garner versus a human accuracy of 72.40%.
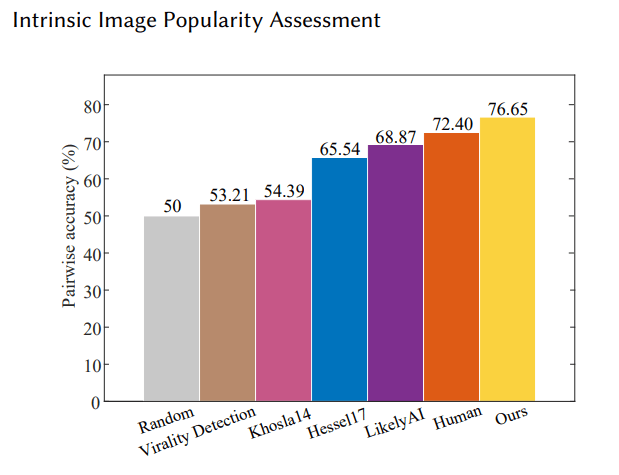
Image Credits: Ding/Ma/Wang (opens in a new window)
I used the model and source code from this paper to come up with how marketers can improve their chances of selecting images that will have the best impact on their content.
Finding the best screen caps to use for a video
One of the most important aspects of video optimization is the choice of the video’s thumbnail.
According to Google, 90% of the top performing videos on the platform use a custom selected image. Click-through rates, and ultimately view counts, can be greatly influenced by how eye-catching a video title and thumbnail are to a searcher,
In recent years, Google has applied AI to automate video thumbnail extraction, attempting to help users find thumbnails from their videos that are more likely to attract attention and click-throughs.
Unfortunately, with only three provided options to choose from, it’s unlikely the thumbnails Google currently recommends are the best thumbnails for any given video.
That’s where AI comes in.
With some simple code, it’s possible to run the “intrinsic popularity score” (as derived by a model similar to the one discussed in this article) against all of the individual frames of a video, providing a much wider range of options.
The code to do this is available here. This script downloads a YouTube video, splits it into frames as .jpg images, and runs the model on each image, providing a predicted popularity score for each frame image.
Caveat: It is important to remember that this model was trained and tested on Instagram images. Given the similarity in behavior for clicking on an Instagram photo or a YouTube thumbnail, we feel it’s likely (though never tested) that if a thumbnail is predicted to do well as an Instagram photo, it will similarly do well as a YouTube video thumbnail.
Let’s look at an example of how this works.

Current thumbnail. Image Credits: YouTube (opens in a new window)
We had the intrinsic popularity model look at three frames per second of this 23-minute video. It took about 20 minutes. The following were my favorites from the 20 images that had the highest overall scores.
Read Full Article





























{kind=link}